微信扫码看作者独家介绍本论文
杨 武,杨 淼,赵 霞
(北京科技大学 东凌经济管理学院,北京 100083)
摘 要:利用中国科技创新景气指数和宏观经济景气指数合成中国科技创新驱动经济增长指数,将该指数划分为5个景气状态预警区间,运用先行合成指数预测模型、判别分析、预警信号灯系统等多种方法对中国科技创新;经济增长预警问题进行研究,规范了区域科技创新驱动经济增长预警研究方法体系。
关键词:科技创新;经济增长;预警方法;先行合成指数预测;ARIMA模型;判别分析;预警信号灯系统
当前,关于景气指数预警的研究多是参考经济景气研究方法,专门针对区域科技创新景气和区域科技创新驱动经济增长的研究较少。区域科技创新驱动经济增长预警研究具有以下4个方面的特点:①不像宏观经济景气有过冷和过热两种状态,区域科技创新驱动经济增长景气只有过冷状态,景气越热说明创新驱动增长状态越好,创新驱动水平越高;②过度依赖传统经验, 对区域科技创新驱动经济增长自身规律掌握不足;③过于强调利用外在方法纠正区域科技创新驱动经济增长过程中出现的偏离;④遇到危机时多采取临时对策,缺少提前监测预警。从上述特点可以看出,当前区域科技创新驱动经济增长研究主要强调对区域科技创新驱动经济增长实际效果和质量的评价,忽视了对区域科技创新驱动经济增长实时状态的监测及未来发展预警研究。
区域科技创新发展如果不能做到从创新逆境向管理顺境扭转, 就可能导致区域科技创新驱动经济增长不景气状态发生, 势必对经济社会发展产生消极影响。因此,建立一套完善有效的区域科技创新驱动经济增长监测预警机制,及时纠偏矫正,使创新驱动增长在正常轨道上运行,并保持在景气或相对景气的安全状态区间内,促进区域科技创新驱动经济平稳高效增长,具有较强的理论意义和现实意义。
当前,预警研究定性方法主要有景气问卷调查法[1-4]、专家评估法(德尔菲预测法、主观概率法、交叉影响法等);定量方法主要有景气指数法(扩散指数、合成指数)、时间序列法[5-7](ARCH模型、GARCH模型、ARIMA模型、移动平均法、指数平滑法、时差相关分析等)、回归分析法[8]、基于概率的模式识别模型[9-12](Bayes最小风险判别规则、人工神经网络、灰色预测、模糊评价等)、投入产出法[13]、主成分分析评价[14]、马尔科夫链[15]等。本文利用中国科技创新景气指数和宏观经济景气指数合成中国科技创新驱动经济增长指数,将该指数划分为5个景气状态区间,运用先行合成指数预测、ARIMA模型、判别分析、预警信号灯系统等多种方法对驱动指数预警问题进行研究。判别分析方法和预警信号灯系统专门针对多属别问题进行预测,适用于区域科技创新驱动经济增长景气状态预警研究;先行合成指数预测方法利用先行合成指数对一致合成指数进行预测,可以验证先行指数对一致指数的领先效果和解释作用,反映两者之间的时序性问题;ARIMA模型根据计量经济模型进行预测,预测结果精确性较高。因此,上述4种方法适合本文研究主题。
预警界线界定的合理性直接影响科技创新驱动经济增长景气状况判断的客观性和科学性。因为科技创新和经济增长指标正常值居多,剩余值围绕正常值呈正态分布排列,所以科技创新驱动经济增长景气预警线可由指标均值和标准差运算得到。参考经济景气预警界线设置方法,科技创新驱动经济增长景气预警线同样设置4个数值:不景气与不太景气的分界线为μ-σ,正常与不太景气的分界线为μ-σ/2,正常与比较景气的分界线为μ+σ/2,非常景气与比较景气的分界线为μ+σ。
判别分析将数量为n个的整体样本看作是p维空间中的n个点,将p维空间划分为不存在共同空间的q个区域,q个区域对应q种类型,由于新样本仍然属于p维空间的一个点,所以也必然属于q区域中的某一类别。判别分析的实质就是分析变量在不同类别中的差别,如果有n个类别,就构建n个判别函数,将待判样本分别代入每个判别函数中计算出n个判别函数值,最大函数值所属判别类别就是待判样本所属组别。根据判别规则不同,判别分析有距离判别、Fisher判别、Bayes判别和逐步判别等方法。由于科技创新驱动经济增长有5种景气状态(非常景气、比较景气、正常、不太景气和不景气),而距离判别需要逐对进行两类之间的判别,判别函数计算量很大,不适合处理多类别判别问题。因此,本文运用后3种判别分析方法进行研究。
(1)Bayes判别。Bayes统计的基本思想是假定对研究对象(总体)在抽样前已有一定认识,用先验概率分布描述这种认识。基于抽取样本再对先验认识进行修正,得到后验概率分布,而各种统计推断都基于后验概率分布进行。将Bayes统计思想用于判别分析,就得到Bayes判别方法。
Bayes判别准则为:设G1,G2,...,Gk为k个p维总体,分别具有互不相同的p维概率密度函数f1(x),f2(x),...,fk(x)。对Rp空间进行不重叠划分D1,D2,...,Dk,若样品X落入Di,则判断此样品属于总体Gi,因此一个判别准则可简记为D=(D1,D2,...,Dk)。
以P(j|i,D)表示在判别准则D下将事实上来自Gi的样品误判为来自Gj的概率,则:
(1)
由此误判造成的损失为c(j|i)j=1,2,...k,j≠i。因此,在一个给定判别准则D下对Gi造成的损失,应该是误判为G1,G2,...,Gi-1,Gi+1,...,Gk的所有损失,按照各误判概率加权求和,即在此判别准则下,将来自Gi的样品错判为其它总体期望损失为(其中c(i|i)=0):
(2)
又由于各总体Gi出现的先验概率为qi(i=1,2,...,k),因此在判别准则D下总期望损失为:
(3)
总期望损失L与判别准则D有关,Bayes判别即选择D=(D1,D2,...,Dk),使L达到最小。
(2)Fisher判别。Fisher判别的基本思路是投影,将k组p维数据投影到某一方向上,使得投影后的组与组之间尽可能分开,借助方差分析思想,从而导出判别函数和建立判别规则。这种方法无需对总体分布作出具体要求,因此适用性较好。
Fisher判别准则为:假定有k个不同的总体G1,G2,…Gk,每个总体样本数分别为n1,n2…nk,每个样本有p个指标,![]() 为第i个总体的第l个观测向量 (i=1,2,…k)。Fisher判别函数为y(X)=a′X,其中a=(a1,...ap)′,则:
为第i个总体的第l个观测向量 (i=1,2,…k)。Fisher判别函数为y(X)=a′X,其中a=(a1,...ap)′,则:
![]()
(4)
(5)
(6)
(7)
为使各区域不存在相交问题,根据Fisher判别原理,a的取值应使组间差最大,组内差最小,即使式(8)最大化:
(8)
B为组间离差阵,C为组内离差阵。
Z=a1x1+a2x2+…anxn
(9)
其中,Z是判别函数,X=x1、x2…xn是反映科技创新驱动经济增长景气状况各指标的线性组合,a=a1、a2…an为判别系数。判别函数最大是指使上述变量线性组合最大的函数组别即为该线性组合所属类别。
(3)逐步判别。Bayes判别和Fisher判别都是用已知的全部变量建立判别函数,但这些变量在判别函数中所起作用不同,如果将判别能力较弱变量保留在判别函数中,可能会干扰判别效果。逐步判别可以筛选出具有显著判别能力的变量并建立判别函数,其做法与逐步回归类似,采用“有进有出”算法,变量按重要性程度逐步引入,每引入一个新变量,就对判别函数中原有变量逐个进行显著性检验,原引入变量也可能由于新变量引入而变得不再显著,因而从判别函数中剔除,当判别函数中无变量需要剔除,剩下变量中也无重要变量可引入时,逐步筛选变量过程全部完成。通过逐步筛选变量方法建立的判别函数保留了所有判别能力比较显著的变量。
根据上文预警界限确定方法,将不景气状态、不太景气状态、正常状态、比较景气状态、非常景气状态分别用红灯、黄灯、绿灯、浅蓝灯、蓝灯5种信号灯表示,每种信号灯都赋予不同分数。信号灯分值给定情况及相对应的景气状态如表1和表2所示。
表1预警信号灯与景气状态对照

表2预警信号灯对应分值

根据区域科技创新景气指数和宏观经济景气指数研究成果,本文将科技创新驱动经济增长指数按照时序性划分为先行指数、一致指数和滞后指数。先行指数由区域科技创新景气先行指数和宏观经济景气先行指数合成,依此类推。先行指标(指数)是景气预警的有效指标(指数),因此先行指标(指数)对一致指标(指数)具有良好的预测效果。
本文运用ARIMA模型建模。首先,运用HP滤波法滤掉长期趋势,再采用ADF检验序列的平稳随机性;序列平稳后(原序列不平稳则进行差分)拟合ARIMA模型,根据AIC和SC准则进行模型识别和定阶;最后,对拟合方程残差序列进行Q统计量检验,保证各阶残差序列均为白噪声。
先行合成指数领先一致合成指数周期为a年, 即:
先行指数预测一致指数(X年)= 一致指数(X-1年)+ 先行指数变化(X-a年) = 一致指数(X-1年)+ 先行指数(X-a年)-先行指数(X-a-1年)
(10)
本文运用中国科技创新景气指数和宏观经济景气指数分别测度科技创新景气和经济景气,数据年份为1991-2014年。中国科技创新景气指数构成指标数据来源于《中国科技统计年鉴》。在构造中国科技创新景气指数时,首先运用PST模型(科技创新过程、结构和时序维度)进行指标初选,再依据数据缺失情况和指标重要性、及时性和波动性最终筛选出32个指标。宏观经济景气指数是由国家统计局中国经济景气监测中心发布的监测宏观经济运行状况的景气指数。中国科技创新景气指数和宏观经济景气指数均运用美国商务部提出的合成指数方法(CI)[16]构造,使用同比增长率循环。宏观经济景气指数是月度数据,根据本文研究需要,对月度数据求和再计算平均合成年度数据。
依据厚今薄古归一化法[17],离现在时刻点越近的科技创新和经济景气指数对当前影响越大,所赋权重也越高;反之越小。这样可对被评价对象历年评价值进行时间加权,从而计算出总体评价值。在时间区间[t1,tn]内,tk时刻指标时间权重为:
(11)
建立分布滞后模型,综合比较各阶方程的DW值、R2、AIC和SC准则、自变量回归值和P值大小,最终确定1991-2014年中国科技创新驱动经济增长滞后期为4年。因此,本文选取前4年中国科技创新景气一致指数时间加权值(为简化处理,其中每年权重为1/4)表示当年科技创新的影响,选取前一年和当年中国宏观经济景气一致指数时间加权值(其中每年权重为1/2)表示当年经济增长的影响,将两者比值表示该年中国科技创新驱动经济增长相对景气水平,从而构建中国科技创新驱动经济增长指数(因滞后期为4年,故舍去1991-1994年指数值)。这种指数加权比值法[18]类似于测度创新效率非参数方法中的指数法[19],如Fisher理想指数和Tornqvist生产率指数,将创新产出作为分母、创新投入作为分子。本文提出的指数加权比值法综合考虑了科技创新驱动经济增长滞后作用和经济增长自身惯性作用,比值大反映科技创新驱动作用较大,经济增长作用较小;反之亦然。
根据中国科技创新驱动经济增长指数与0、1两个界限值比较结果,本文将中国科技创新驱动经济增长实际效果分为强驱动、耦合驱动和弱驱动3种情况,具体如下:
(12)
其中,SIDEDINDEX为科技创新驱动经济增长指数;W(TCI)和W(ECI)分别为当年科技创新景气指数和宏观经济景气指数时间加权值。
SIDEDINDEX>1为强驱动,则未来呈收敛式发展;SIDEDINDEX=1为耦合驱动,则未来呈融合式发展;0<SIDEDINDEX<1为弱驱动,则未来呈发散式发展。
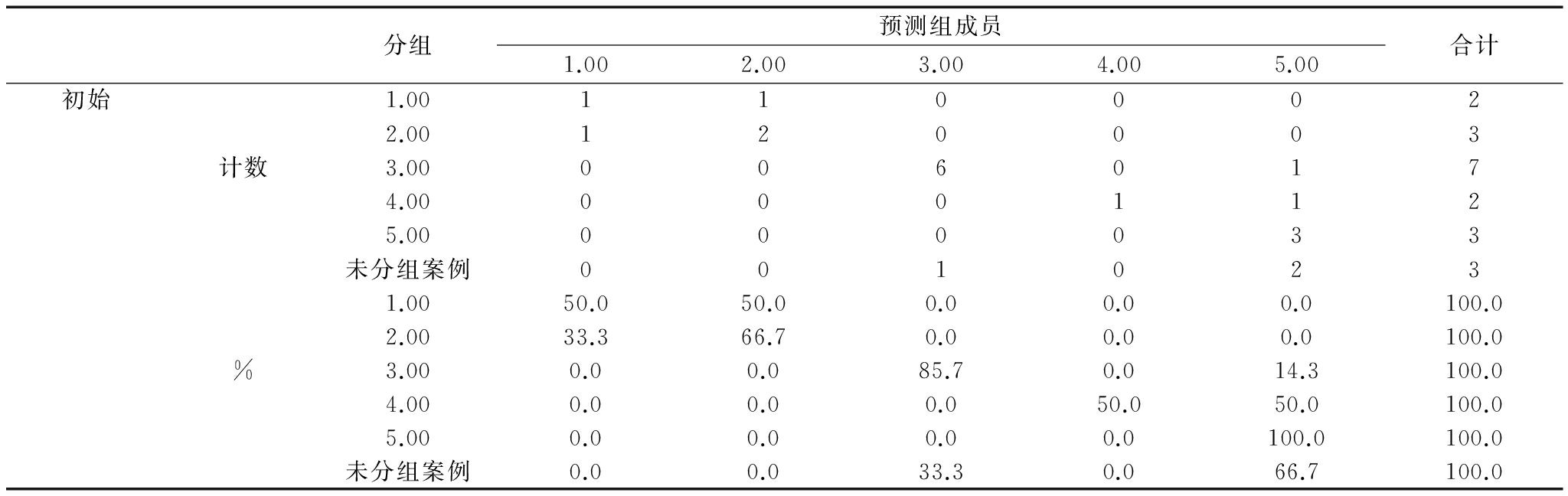
(1)Bayes判别。本文运用中国科技创新驱动经济增长一致指数计算结果,应用Bayes判别进行分析。由于指数时间为1995-2014年,为验证多种方法分析结果,本文采用1995-2011年数据为分析变量,2012-2014年数据为验证变量,考察3年驱动指数景气状态。其中,Group表示各年份中国科技创新驱动经济增长一致指数景气状态:1表示不景气,2表示不太景气,3表示正常,4表示比较景气,5表示非常景气。
经测算发现,中国科技创新景气一致指数指标大中型企业技术改造经费(记作TCI4)、宏观经济景气一致指数指标工业生产者出厂价格指数(记作ECI1)、科技创新驱动经济增长先行指数(记作TDE)和宏观经济景气先行指数(记作ECI)变量均值存在显著差异,各变量显著性水均小于0.05。因此,本文选取以上4个指标作为判别分析变量,检验结果如表3所示。表4给出了贝叶斯判别函数系数,由此可得到中国科技创新驱动经济增长一致指数景气状态的5个判别函数。表5给出回判结果,Bayes判别准确率为76.5%。
表3组均值均等性检验结果
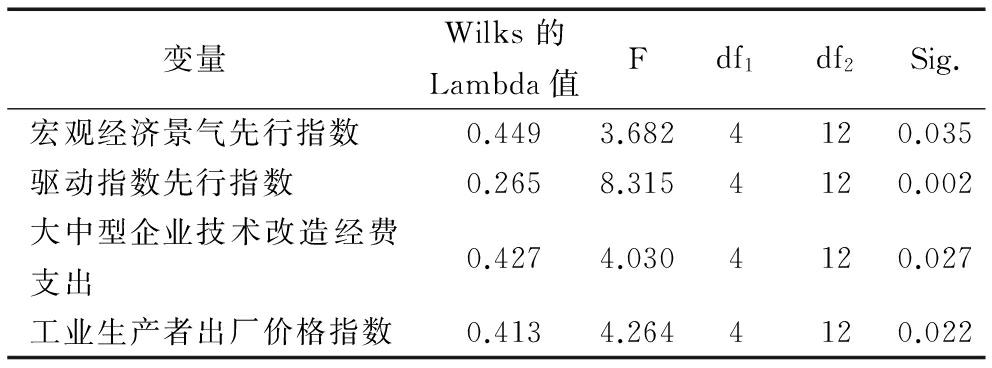
表4贝叶斯判别函数系数

表5贝叶斯判别回判结果
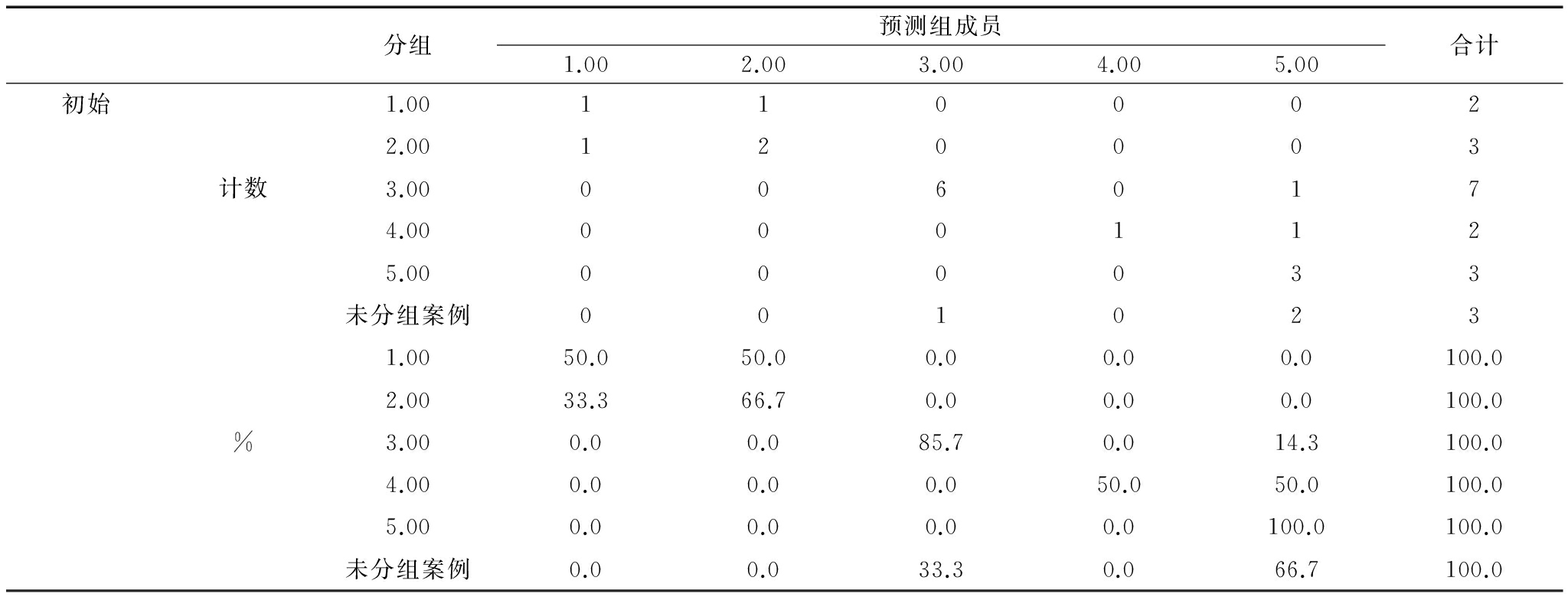
注: 已对初始分组案例中的 76.5% 个对象进行了正确分类
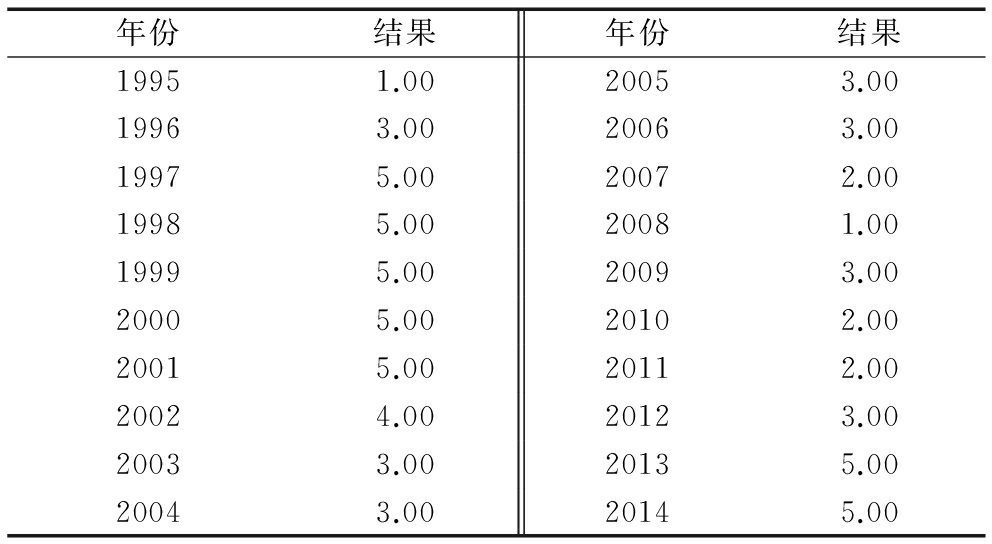
表6给出最后分类结果,并对2012-2014年中国科技创新驱动经济增长一致指数景气状态进行预测。判别结果显示,2013-2014年均为非常景气状态,2012年为正常状态。
表61995-2014年贝叶斯判别分类结果
(2)Fisher判别。本文运用中国科技创新驱动经济增长指数计算结果,按照Bayes判别操作步骤,对2012-2014年中国科技创新驱动经济增长一致指数景气状态进行判别。Fisher判别与Bayes判别的不同之处在于“判别分析:统计量”对话框“函数系数”栏中选择“未标准化”。
表7和表8分别给出Fisher标准化判别函数系数和非标准化判别函数系数。
表7Fisher判别标准化判别函数系数

表8Fisher判别非标准化判别函数系数
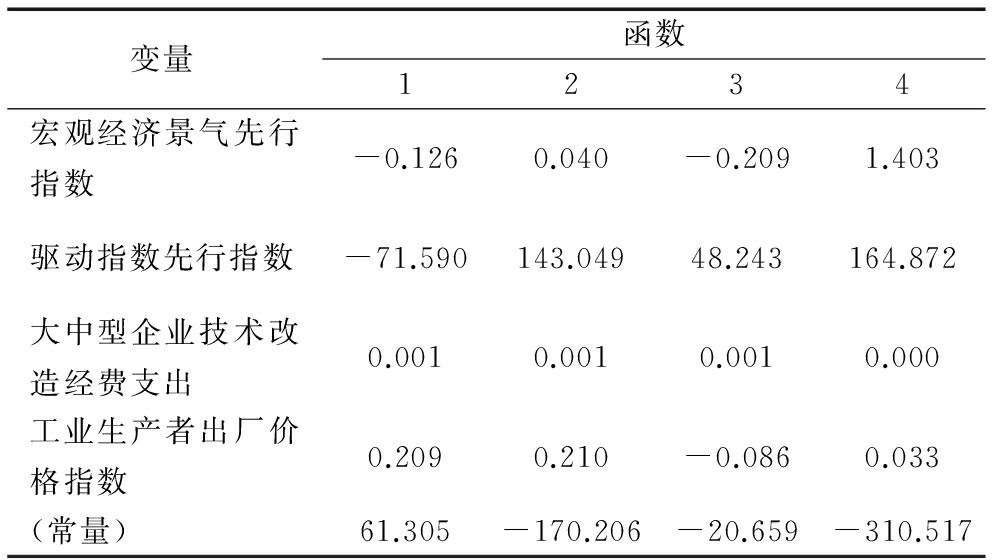
注:表中系数为非标准化系数
表9显示4个特征值、所解释方差百分比、累积百分比及正则相关系数,其中第一判别系数解释方差能力较强,为81.1%;第二判别系数仅解释16.6%,相对而言第一判别函数更重要。
表9Fisher判别特征值
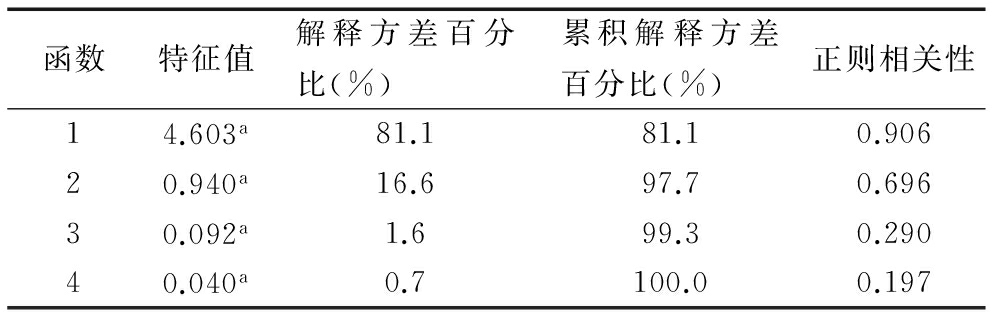
注:分析中使用了前 4 个典型判别式函数
表10给出Fisher判别回判结果,可以看出该结果与Bayes判别回判结果相同。
表11给出Fisher判别分类结果,与Bayes判别分类结果完全一致。
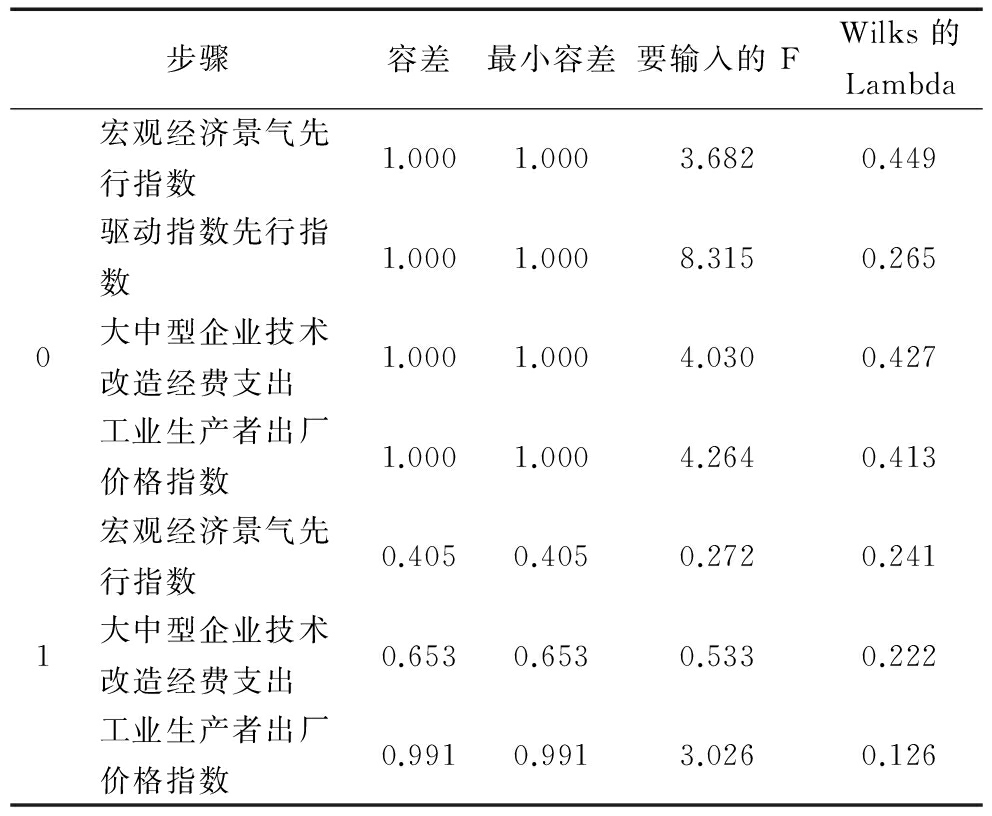
(3)逐步判别。本文运用中国科技创新驱动经济增长一致指数计算结果,对2012-2014年中国科技创新驱动经济增长一致指数景气状态进行逐步判别。表12反映每一步变量加入和剔除的情况,表13和表14反映进入判别函数和未进入判别函数的变量。从中可以看出,经过筛选,变量“中国科技创新驱动经济增长先行指数”保留在判别函数中,变量“宏观经济景气先行指数”、“大中型企业技术改造经费”和“工业生产者出厂价格指数”从判别函数中剔除。从现实情况看,科技创新驱动经济增长先行指数可以预测科技创新驱动经济增长变化趋势,其最能反映一致指数景气状态动态变化情况。
表15表明,从显著性水平可知,包含变量TDE的判别函数比较显著和有效。
根据表16得到中国科技创新驱动经济增长一致指数景气状态的5个判别函数方程。将2012年中国科技创新驱动经济增长先行指数值代入5个方程,比较得出5个函数值大小,其中取值最大的函数值对应类别就是2012年一致指数所属类别。经计算发现,F3值最大,所以2012年中国科技创新驱动经济增长指数属于正常景气状态。
表10Fisher判别回判结果
注:已对初始分组案例中的 76.5%个对象进行正确分类
表111995-2014年Fisher判别分类结果
表17给出逐步判别回判结果,逐步判别准确率为64.7%,该结果不同于Bayes判别和Fisher判别分类结果。
表18给出逐步判别最后分类结果,对2012-2014年一致指数景气状态进行预测,其中2013年和2014年属于非常景气状态,2012年属于正常状态。预测结果与前文Bayes判别和Fisher判别分类结果一致。
预警信号灯系统由入选综合指标判别分析的指标信号灯组成。表19为1995-2014年中国科技创新驱动经济增长指数单项指标和综合指标变动情况,从中可以观测到中国科技创新驱动经济增长景气长期变化趋势。
表12逐步判别法筛选变量过程

注:在每个步骤中,输入最小化整体 Wilks 的 Lambda 的变量;步骤最大数目是 8;要输入的最小偏 F 是 3.84; 要删除的最大偏 F 是 2.71;F 级、容差或 VIN 不足以进行下一步计算
表13逐步判别分析变量
表14逐步判别不在分析中的变量
通过表19可以看出,大中型企业技术改造经费支出(TCI4)和工业生产者出厂价格指数(ECI1)与综合指标中国科技创新驱动经济增长一致指数(TDE)的重合率分别为15%和20%,而宏观经济景气先行指数(ECI)与驱动指数的重合率为10%。这说明,TCI4和ECI1与TDE的相关性较高,而宏观经济景气先行指数反映经济增长率预期变化情况,其与科技创新驱动经济增长变化率不直接相关。
中国科技创新驱动经济增长一致指数(TDE)预警信号灯显示,2012-2014年景气状态分别为正常、比较景气和比较景气。与前3种判别分组分析结果相比,逐步判别分组结果准确率最低,为64.7%,而贝叶斯判别和费歇判别准确率均为76.5%。这说明,逐步判别通过筛选有显著能力的判别变量建立判别函数并未显著提高判别分组分析准确率,与预期设想不符,这可能源于先行指数对一致指数的引领作用和预测作用不强,还需要其它指标补充。
中国科技创新驱动经济增长一致指数序列记为y(y={yt}),通过对一致指数进行趋势分解,观察过滤掉长期趋势的序列波动循环情况,可以更加准确地判断序列波动变化情况。
表15Wilks的Lambda值

表16逐步判别的Bayes判别函数系数

表17逐步判别回判结果
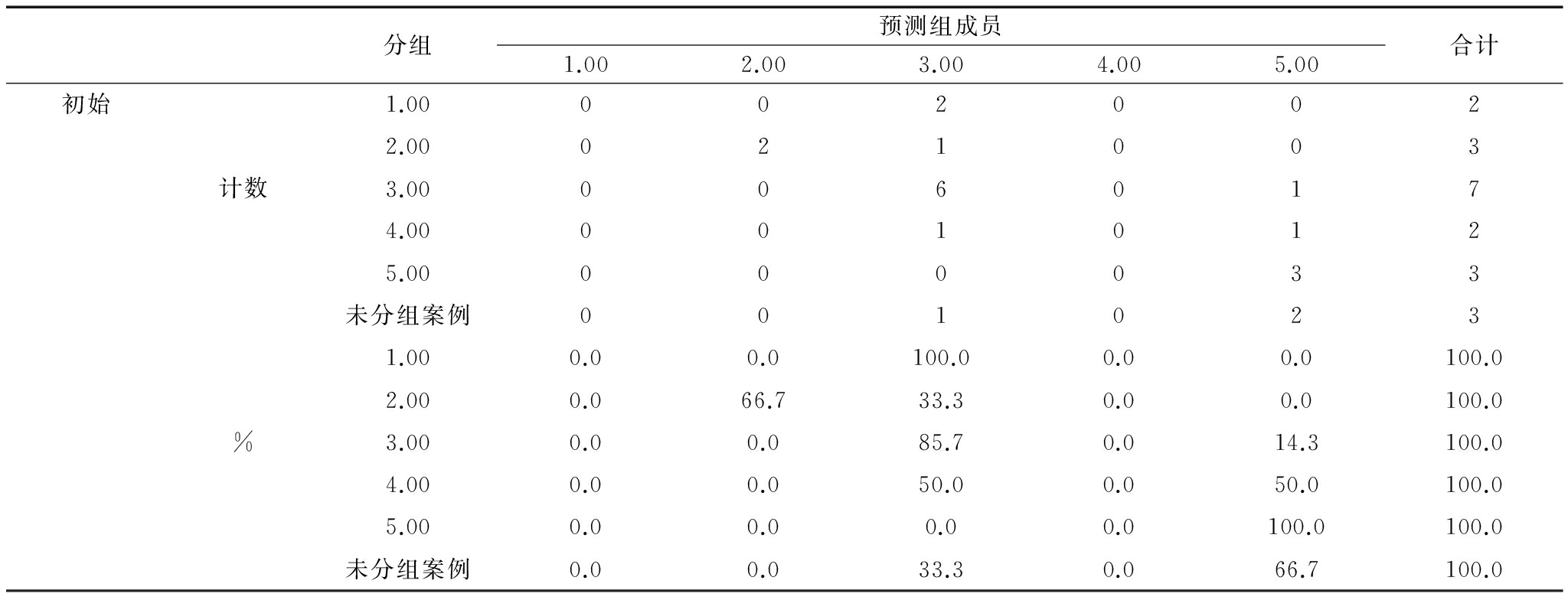
注:已对初始分组案例中的 64.7%个对象进行了正确分类
表181995-2014年逐步判别分类结果
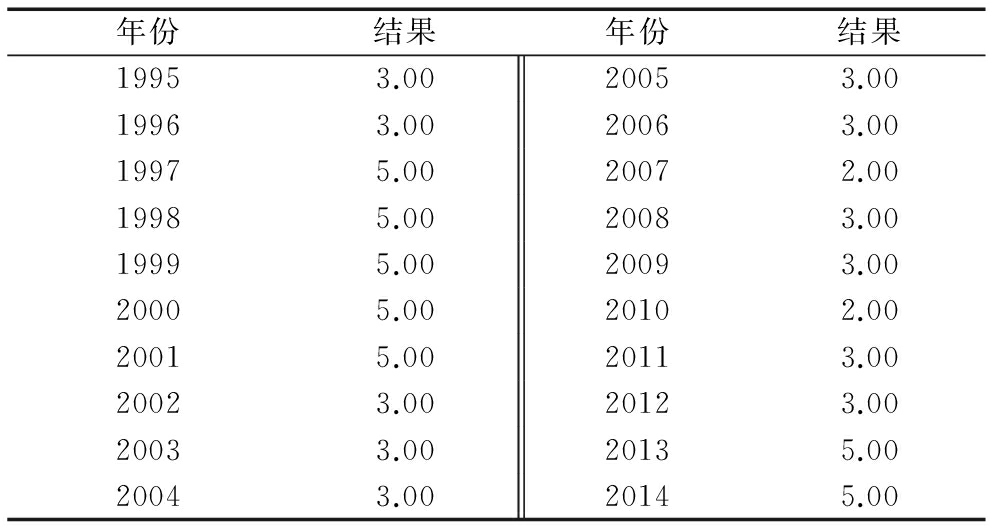
表191995-2014年中国科技创新驱动经济增长预警信号灯系统
EVIEWS软件显示,原序列与循环序列波动变化情况基本一致,趋势序列呈一定下滑趋势。可以看出,中国科技创新驱动经济增长一致指数序列呈相似波动变化,是非随机序列。
对一致指数采用ADF检验其平稳性。检验结果表明,ADF检验统计量值虽然小于10%显著性水平的临界值,但大于显著性水平1%和5%时的临界值,说明在1%和5%显著性水平下是非平稳序列,存在单位根。因此,本文对其进行差分运算达到ARIMA模型需满足的序列平稳性条件。
令dy=yt-yt-1,d{dy}=yt-2yt-1+yt-2,对时间序列d{dy}进行ADF检验。结果表明,ADF检验统计量值分别小于10%、5%和1%显著性水平下的临界值。经过二阶差分时间序列的d{dy}没有单位根,拒绝原假设,二阶差分后的d{dy}是平稳序列。根据上文对一致指数的检验,经过二阶差分处理后的d{dy}满足ARIMA模型建模条件。
时序数据d{dy}自相关系数在3阶后突然趋于0,在5阶后受正向影响后逐渐趋于零,偏相关系数在3阶后突然趋于0。通过EVIEWS6.0软件对ARMA(3,3)和ARMA(3,5)模型进行拟合发现,ARMA(3,3)的AIC值和SC值均小于ARMA(3,5)的AIC值和SC值,故选择ARMA(3,3)模型。
运用EVIEWS6.0软件对模型残差序列进行白噪声检验发现,模型残差序列均在两倍标准差内,自相关系数绝对值均小于0.4,序列残差是随机的,说明模型各阶残差均为白噪声。因此,ARMA(3,3)模型满足要求,可用于预测研究。本文运用ARMA(3,3)模型对2015年和2016年的一致指数进行预测,结果如表20所示。
表20中国科技创新驱动经济增长一致指数预测结果

图1显示,中国科技创新驱动经济增长先行指数波峰波谷平均领先一致指数波峰波谷1年。因此,综合而言,先行指数平均领先一致指数1年。随后,本文将2014年先行指数与预测出的2015年一致指数进行比较,判断先行指数领先及预测效果(见表21)。
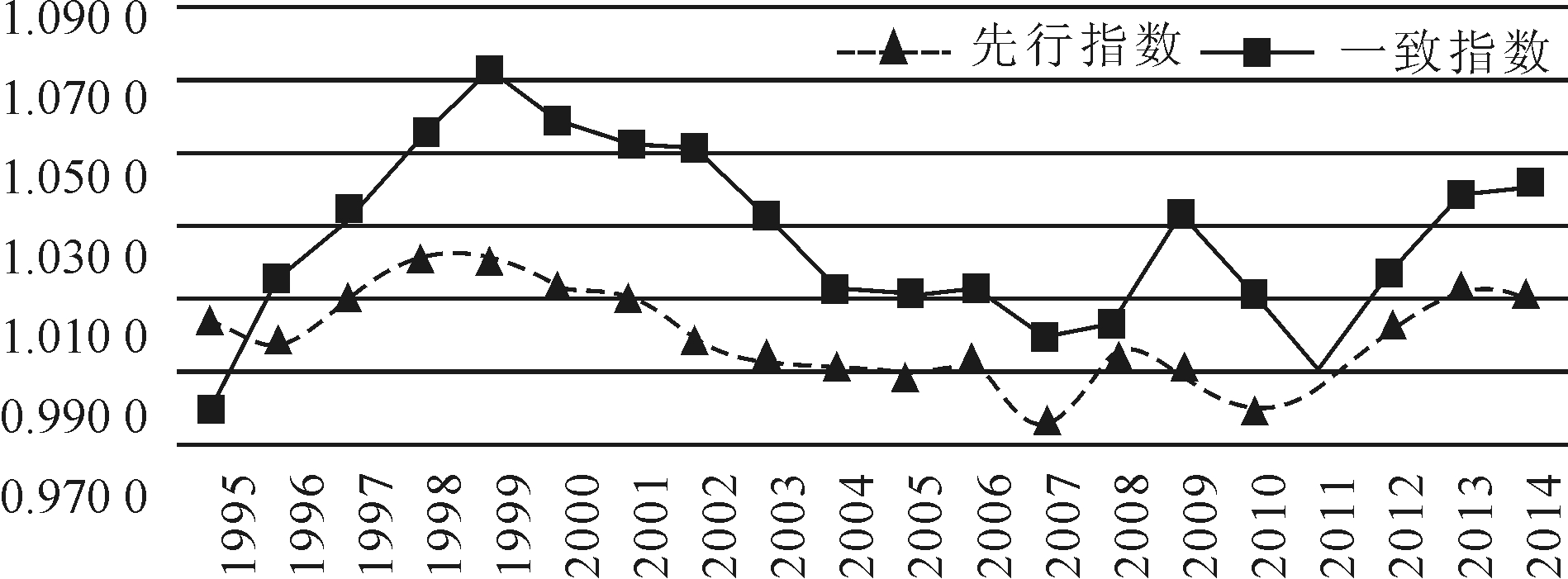
图11995-2014年中国科技创新驱动经济增长先行指数与一致指数
表21先行指数变化与ARMA模型预测的一致指数变化比较
根据表21,先行指数变化与预测的一致指数变化在数值上不严格相同,但振幅基本相似。当先行指数变化较大时,预测的一致指数也产生较大变化;反之亦然。两年呈相同变化趋势,先行指数上升时,预测的一致指数也上升;反之亦然。
先行指数预测的一致指数(2015年)
= 一致指数(2014年)+ 先行指数变化(2014年)
= 一致指数(2014年)+ 先行指数(2014年)- 先行指数(2013年)
由先行指数预测的2015年中国科技创新驱动经济增长一致指数为103.91,由ARMA模型预测的一致指数为103.61,两者相差0.30(见表22)。这说明,本文合成的先行指数能够较好地预测一致指数,但差异随着预测时长而逐渐累加,说明先行指数只能短期预测一致指数变化,不能进行中长期预测。图2显示,由先行指数预测的一致指数和ARMA模型拟合预测的一致指数具有较高的关联性。先行指数预测的一致指数共有6个转折点,ARMA模型拟合预测的一致指数也有6个转折点,转折方向相似,转折时间前后相差不超过1年。
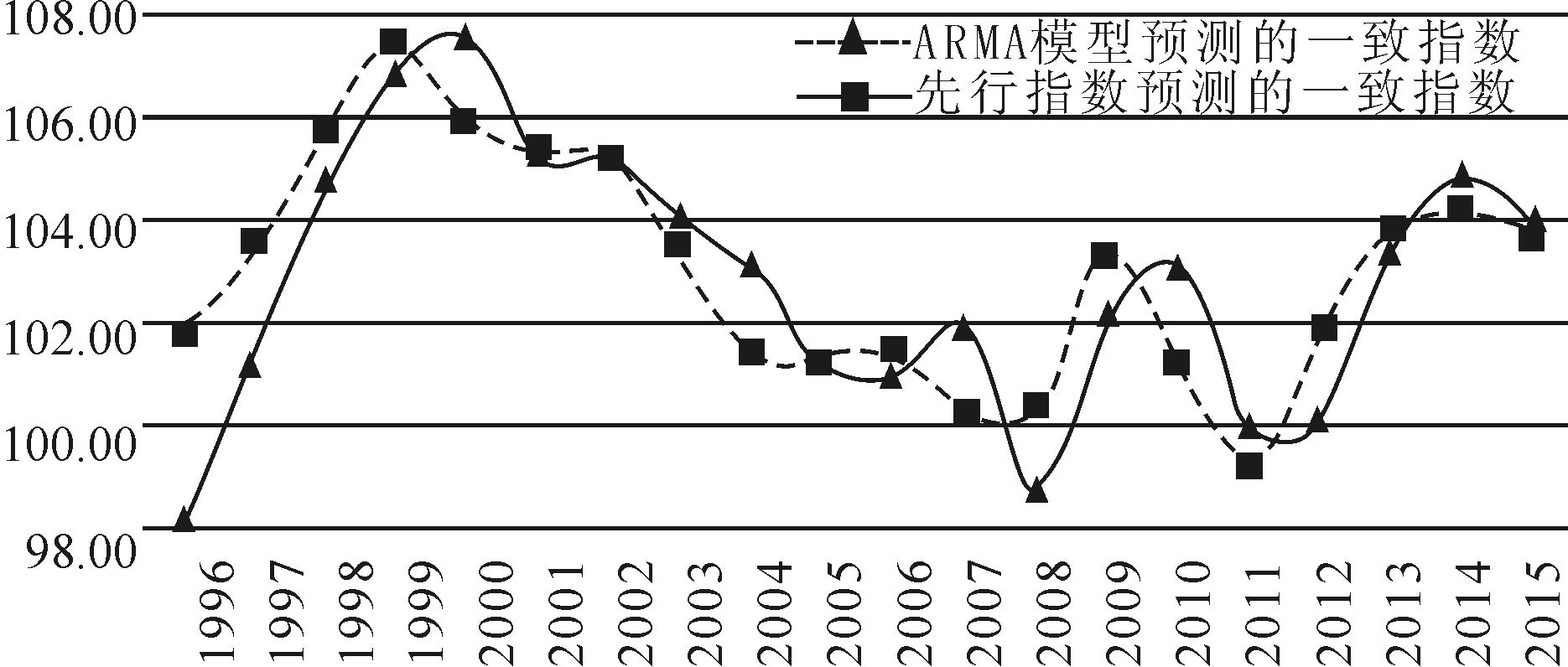
图21996-2015年ARMA模型拟合预测与先行指数预测趋势
表22先行指数预测一致指数与ARMA模型预测一致指数比较

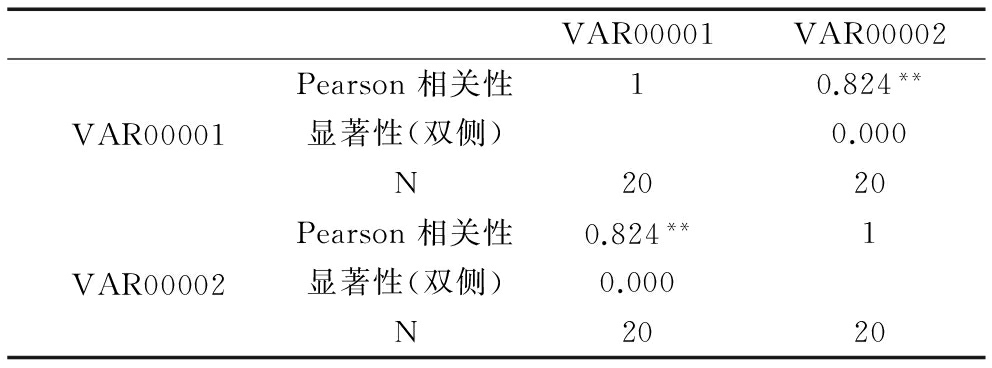
将先行指数预测的一致指数序列与ARMA模型拟合预测的一致指数序列进行Pearson相关性分析,结果见表23。
表23Pearson相关性分析结果
注:**表示在 0.01 水平(双侧)上显著相关
两列数据的Pearson相关系数为0.824,双侧显著性检验P值为0.000,说明两列数据存在较强的线性相关关系。因为Pearson相关系数仅能反映线性相关关系,而不能反映非线性关系。因此,需要通过散点图来验证两者间的相关关系,如图3所示。
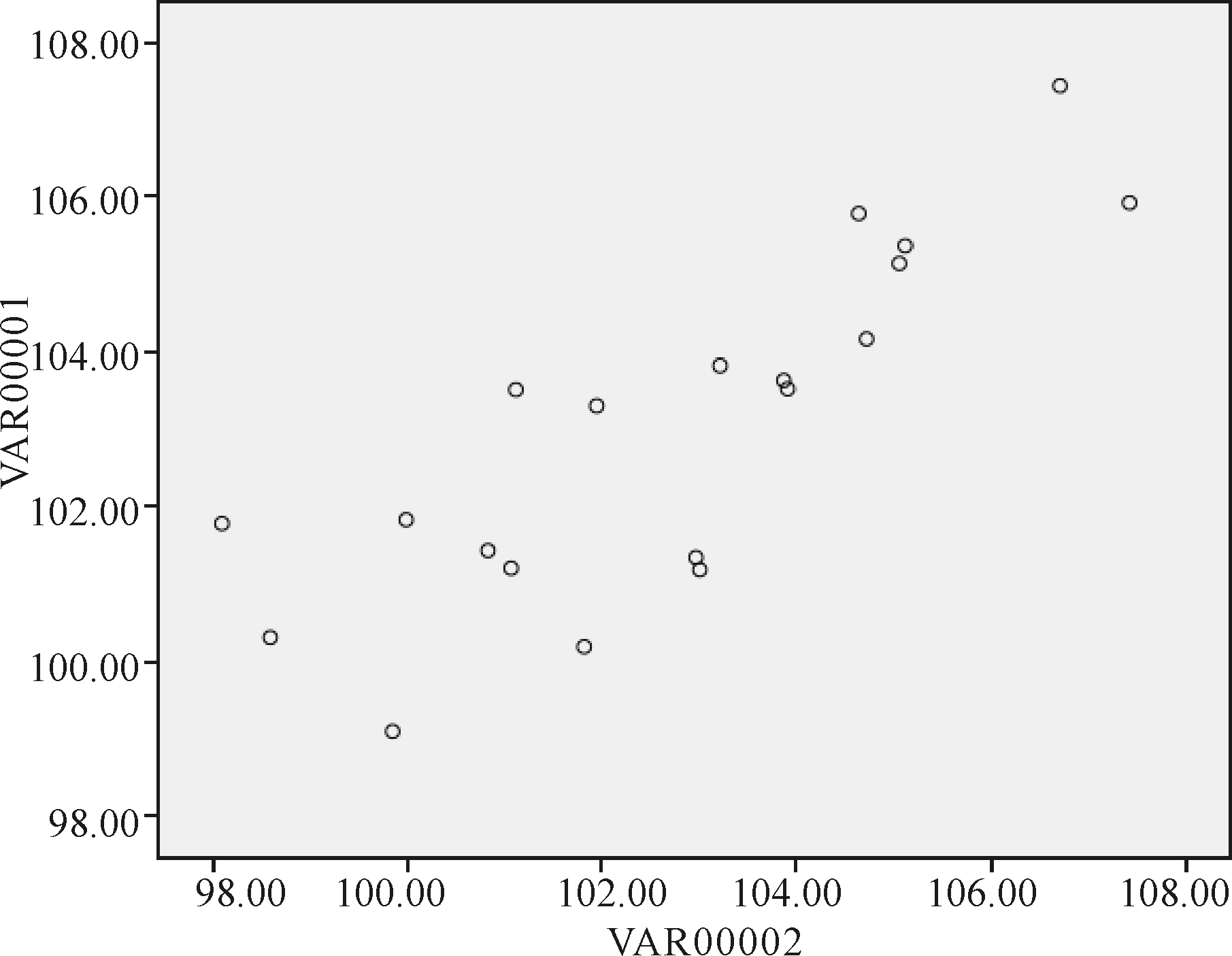
图3先行指数预测数列与ARMA模型拟合预测数列
注:VAR00001为先行指数预测的一致指数序列,VAR00002为ARMA模型预测的一致指数序列
由图3可以看出,先行指数预测数列与ARMA模型拟合预测数列存在较明显的正相关关系,结合上文得出的Pearson相关系数,说明两者正向线性关系比较显著,数据拟合效果较好。
基于先行指数对一致指数具有较好的领先预测作用,本文以先行指数作为预测指标,运用中国科技创新驱动经济增长先行指数对一致指数进行预测,构造ARIMA模型进行预测效果对比分析;运用3种判别分析方法对中国科技创新驱动经济增长综合指标进行预警研究,构建预警信号灯系统进行预警效果对比分析。本文主要结论如下:
(1)运用中国科技创新驱动经济增长先行指数和ARIMA模型对一致指数进行预测研究,应用判别分析和预警信号灯系统对一致指数进行预警研究。结果表明,上述方法对科技创新驱动经济增长景气进行预测预警研究具有一定合理性和可行性,并且规范了科技创新驱动经济增长景气预警研究方法体系。
(2)运用先行指数和ARIMA模型分别对一致指数进行预测研究的实际效果相似,基于先行指数预测得出的一致指数数值稍大,这可能源于迭代计算误差。在3种判别分析方法中,贝叶斯判别和费歇判别预警结果一致。与预警信号灯系统计算结果相比,逐步判别预警效果最差,与预期设想不符,这可能源于所选指标“科技创新驱动经济增长先行指数”对一致指数的引领预测作用不强,还需要其它补充指标,这也反映出科技创新驱动经济增长具有动态变化规律。
(3)基于先行指标(或指数)对一致指标(或指数)进行预测预警研究,表明先行指标(或指数)对一致指标(或指数)具有较好的解释作用,这类似于宏观经济景气先行指数对一致指数、区域科技创新景气先行指数对一致指数的领先效果和解释作用。
参考文献:
[1] 中国企业家调查系统.企业经营者对宏观形势及企业经营状况的判断、问题和建议——2015·中国企业经营者问卷跟踪调查报告[J].管理世界,2015(12):41-57.
[2] 朱松,杜雯翠,高明华.行业景气程度、政府支持力度与企业扩张决策——基于中小企业调查问卷的分析[J].财经研究,2013(10):133-144.
[3] 王呈斌,谢守祥.后危机时代的中小企业景气状况及其特征分析[J].经济社会体制比较,2012(1):203-210.
[4] 杨武,杨淼.企业科技创新景气问卷调查研究——以深圳市企业为例[J].科技进步与对策,2017,34(5):73-79.
[5] 龙会典,严广乐.基于SARIMA、GM(1,1)和BP神经网络集成模型的GDP时间序列预测研究[J].数量统计与管理,2013(5):814-822.
[6] 王立柱,刘晓东.Granger相关性与时间序列预测[J].控制与决策,2014(4):764-768
[7] 王德青,王斐斐,朱万闯.基于EMD技术的非平稳非线性时间序列预测[J].系统工程,2014(5):138-143.
[8] 胡泽文,武夷山.科技产出影响因素分析与预测研究——基于多元回归和BP神经网络的途径[J].科学学研究,2012(7):992-1004.
[9] 张立军,王瑛,刘菊红.基于贝叶斯判别分析的上市公司财务危机预警模型研究[J].商业研究,2009(4):112-114.
[10] 陈文韬,李琳.基于BP人工神经网络的知识创新能力的区域差异研究[J].科技进步与对策,2008,25(9):149-152.
[11] 李文杰,化存才,何伟全,等.网络舆情事件的灰色预测模型及案例分析[J].情报科学,2013(12):51-56.
[12] 葛秋萍,汪明月.产学研协同创新技术转移风险评价研究——基于层次分析法和模糊综合评价法[J].科技进步与对策,2015,32(10):107-113.
[13] 李宝瑜,张靖.GDP核算口径下投入产出表调整与预测方法研究[J].数量经济技术经济研究,2012(11):149-160.
[14] 林海明,杜子芳.主成分分析综合评价应该注意的问题[J].统计研究,2013(8):25-31.
[15] 李永立,罗鹏,张书瑞.基于决策分析的社交网络链路预测方法[J].管理科学学报,2017(1):64-74.
[16] JAMES H STOCK, MARK W WATSON. New Indexes of coincident and leading economic indicators[J].NBER Macroeconomics Annual,1989(5):351-394.
[17] 陈国宏,李美娟.基于总体离差平方和最大的区域自主创新能力动态评价研究[J].研究与发展管理,2014,26(5):43-53.
[18] 王伟光,马胜利,姜博.高技术产业创新驱动中低技术产业增长的影响因素研究[J].中国工业经济,2015(3):70-82.
[19] 余冬筠,魏伟忠.区域创新效率评价研究综述[J].技术经济,2010(10):44-48.
Yang Wu ,Yang Miao, Zhao Xia
(DonLinks School of Economics and Management ,University of Science and Technology Beijing, Beijing 100083,China)
Abstract:In this paper, China's economic growth driven by scientific and technological innovation boom index is synthesized by using China's scientific and technological innovation boom index and the macroeconomic boom index.The driven index is divided into five boom warning interval.The paper studies the early warning of economic growth driven by China's scientific and technological innovation by using the methods of leading composite index prediction,ARIMA model,discriminant analysis and early warning signal lamp system.The paper further standardizes the research method system on early warning of economic growth driven by regional science and technology innovation.
Key Words:Economic Growth Driven; Scientific and Technological Innovation; Early Warning Methods;Leaeding Composite Index Forecasting;Arima Model; Discriminant Analysis; Early Warning Signal System
收稿日期:2017-05-04
基金项目:国家自然科学基金项目(71273025)
作者简介:杨武(1961-),男,山东临沂人,博士,北京科技大学东凌经济管理学院教授、博士生导师,研究方向为创新管理;杨淼 (1989-),男,北京人,北京科技大学东凌经济管理学院博士研究生,研究方向为创新管理;赵霞(1972-),女,山东淄博人,北京科技大学东凌经济管理学院博士研究生,研究方向为创新管理。
DOI:10.6049/kjjbydc.2017030221
中图分类号:F204
文献标识码:A
文章编号:1001-7348(2018)04-0001-09
(责任编辑:王敬敏)