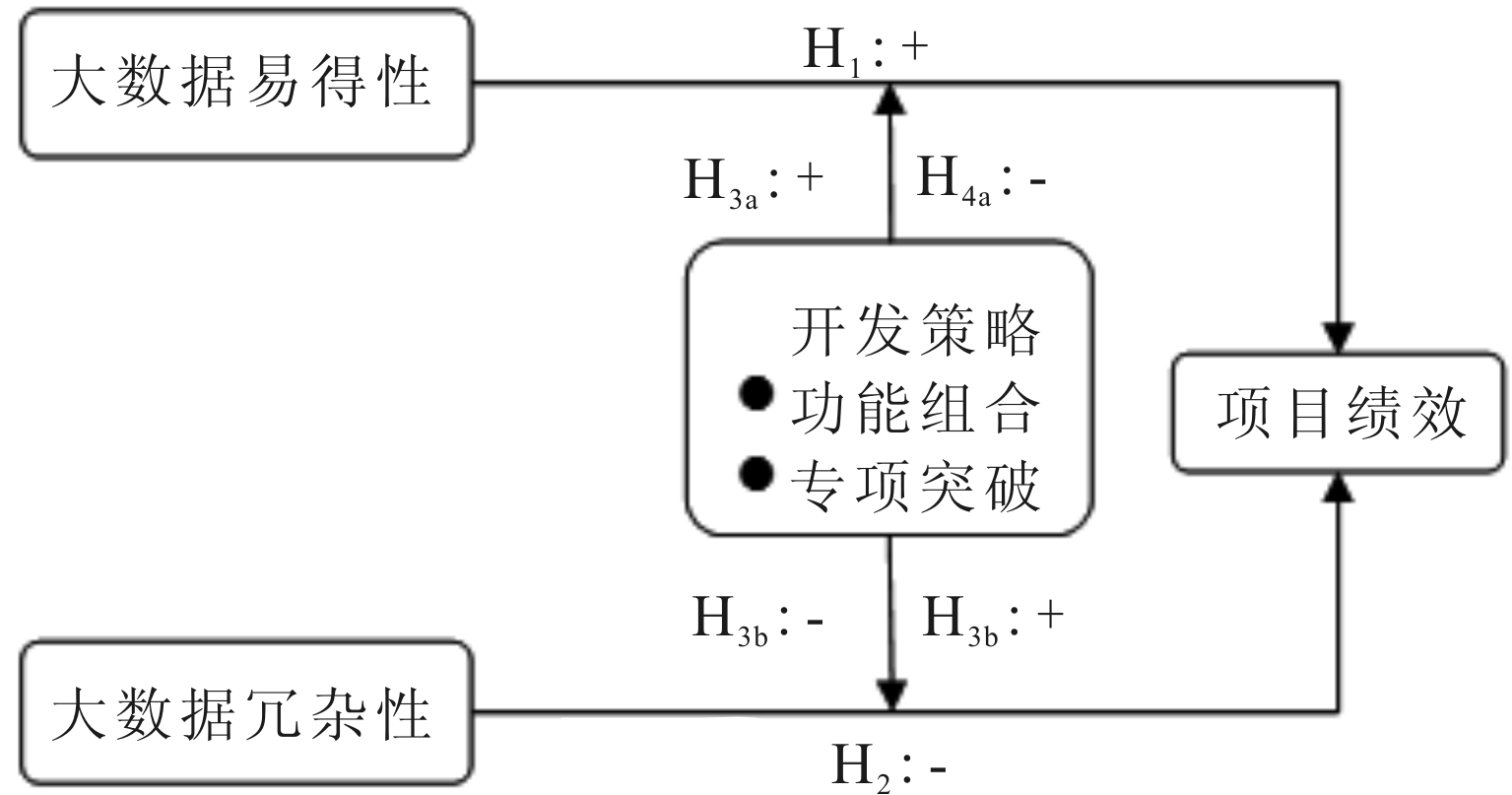
图1 概念模型
摘 要:对知识密集型的IT外包行业来说,大数据环境成为接包企业潜在的知识来源。然而,大数据环境是否真的促进IT接包项目绩效?如何从中获益?现有文献对这些问题缺乏研究。基于资源编排理论,探讨了大数据易得性和冗杂性对IT接包项目绩效的直接影响,检验了功能组合和专项突破两种软件开发策略的调节作用,提出6条假设,采用195个IT外包项目数据进行检验。研究发现,大数据易得性显著提高接包项目绩效,而大数据冗杂性显著降低项目绩效;功能组合策略增强而专项突破策略削弱了大数据易得性对项目绩效的促进作用;两种开发策略对大数据冗杂性与项目绩效关系的调节作用不显著。
关键词:大数据易得性;大数据冗杂性;IT外包;功能组合策略;专项突破策略
自麦肯锡在《大数据:下一个前沿,竞争力、创新力和生产力》中大力宣扬大数据( Big Data)以来,大数据已经成为信息技术和管理领域的新热点。移动互联、云计算、Web 2.0、自媒体等新一代信息技术的普及让大数据涌现为新的环境维度。尽管对大数据缺乏统一界定,但众多学者和企业家都认为大数据环境中蕴含用户痕迹、共享性知识、实时信息、开放式数据等决定竞争力的重要资源。对知识密集型的IT服务外包行业来说,大数据环境已经成为获取资源的重要渠道。在研究访谈中,多位项目经理谈到在项目开发过程中常常从外部大数据环境中寻求有用资源。例如,成熟的开源代码、软件设计诀窍、开发流程知识、业务领域知识等。然而,多位项目经理也对如何利用大数据环境中的资源产生了诸多疑问。尽管大数据环境中蕴含大量有价值的资源,但这些资源也具有重复性、差错性、价值稀薄等缺点。一些项目经理埋怨大数据环境有时使他们更加低效,如需要花费很长时间来筛除大量价值低端的数据,很多不相关或者存在争议的信息让开发人员对于问题的理解变得更加模糊,使人们既浪费了精力又没有得到有效帮助。
因此,是否每个企业都能从外部大数据环境中获益?哪些策略能够在大数据环境中提高项目绩效?当前的大数据研究未能给出满意回答。目前,大数据研究主要集中在两个方面:一是从技术视角探索大数据挖掘方法,强调通过大数据处理,从海量数据中提取有价值的知识[1-3];二是从管理视角,研究企业如何利用大数据推动管理创新,运用大数据分析技术进行鉴别、关联、重组,识别和创造新知识,尽可能发现潜在、隐藏和更有价值的关系。以知识内容、知识关联、知识动态利用为核心,解决基于知识和分析才能化解的问题[4-6]。
这些研究在以下方面存在不足:首先,通过对大数据的处理、挖掘,获取到的知识是否对企业有用?大数据环境有数据量、更新速度、价值密度等多个维度,企业面临的大数据环境在不同维度存在较大差异。尽管以往研究认为大数据对企业有潜在价值,然而这些研究未能深入分析大数据环境的不同维度对企业的影响。其次,管理视角的研究未能深入分析使企业从大数据环境获益的策略。面临大数据环境,采用何种策略是企业关心的核心问题之一,这是因为采用不同策略的获益程度也存在差异。然而,由于目前的研究仍然处于探索阶段,未能对此问题给出满意回答。另外,这些研究局限于案例和概念性分析,缺少更大规模的实证证据。
针对以往研究不足和访谈中IT项目经理的疑问,本研究以资源编排理论为基础,以IT服务外包项目为研究情景,分析大数据环境的不同维度对IT接包项目绩效的影响,探讨软件开发策略的调节作用。
1.1 理论背景
对于IT服务外包企业而言,大数据正在成为重要的环境维度之一。与竞争、技术、需求不确定等环境特征不同,大数据环境给企业带来的是丰富的知识资源、信息和链接。资源基础理论认为稀缺、有价值、难以模仿、难以替代的资源是竞争优势的重要来源[7][8]。核心资源稀缺一直是制约我国IT接包企业的重要瓶颈[9]。接包企业由于缺少核心程序模块资源、高质量的技术人员以及接包项目的具体行业知识,因而难以快速高效地完成接包项目。然而,大数据环境为企业建造了巨大的外部资源池,为这一问题的解决提供了难得的机遇。IT服务外包企业可以从大数据环境中提取大量免费的信息和知识,例如企业可以免费获得大量的开源程序包,并且随着开源软件社区越来越成熟,开源模块可以便捷地与项目其它模块集成。另外,接包企业还可以获得社区、顾客、其它团体共享的关键知识和新技术,可以与IT领域内高技能人员迅速建立链接。这些都大大降低了资源获取难度,提高了资源多样性[10]。因此,大数据环境中的外部资源和知识对IT服务外包企业接包项目的完成有重要潜在影响。
尽管如此,大数据环境的复杂性也给IT外包企业的资源获取和利用带来了不确定性。首先,大数据环境在带来大量资源的同时,也带来许多虚假甚至错误的信息。大数据环境可以分为资源易得性和资源冗杂性两种情况。易得性主要针对大数据环境中资源的量及获取成本,冗杂性主要针对大数据环境中资源冗余、重复、差错的程度。因而,大数据环境的不同维度对IT接包项目的完成有不同作用。其次,为了更好地实现从大数据环境中受益,企业需要根据所处大数据环境,针对性地设计资源编排利用方式。资源编排(Resource Orchestration)突破了资源基础理论框架,提出了新的理论视角,它主要强调将资源协调、组合出竞争优势[11-12]。该理论认为资源的价值决定于资源编排方式,同样的,由于编排方式不同资源将产生不同效果。该理论强调企业需要开展行动、有效管理资源,使资源潜在优势得以充分发挥。Sirmon等、Carnabuci[12]和Operti等[13]认为不应仅仅关注拥有多少有价值的资源,还应该关注企业是如何调配、组合利用资源的,包括构建资源组合、将资源变成能力、利用资源实现竞争优势等。Carnes等[14]认为由于现有活动和规则的惯性,资源组合中会面临诸多困难。能否有效组合利用资源受到战略导向与编排方式的影响,企业可以通过不同资源编排方式更好地实现资源系统的最终目的[15]。以往研究指出,企业可以通过现有资源的重新编排,集中突破资源瓶颈[16-17]。
在IT服务外包项目中,资源编排方式区分为组合策略和突破策略,分别对应着项目层面的两种,即功能组合式开发和专项突破式开发两种策略。这两种开发策略在资源组合利用方面明显不同,并使大数据资源产生不同效果。组合式开发是指改变产品组件连接方式,不改变组件核心概念、基础设计,在开发过程中实现对现有知识的重新配置[16]。因此,需要掌握每个组件的接口知识,以及组合不同组件的架构能力,而无需掌握每个组件的核心知识[18]。专项突破式开发是指针对某个组件或某个技术进行攻关,其核心设计概念和基础逻辑都发生了变化。因此,需要掌握的不是每个组件的接口知识以及组合能力,而是系统化的高质量知识。因此,两种资源编排方式存在明显差异,使外部大数据资源发挥不同作用,对大数据环境与项目绩效关系起到一定的调节作用。
1.2 研究假设
1.2.1 大数据易得性与绩效
资源基础观认为企业拥有资源的价值和多少影响企业绩效,后来的研究者更将外部资源视为关键来源[8,19-20]。首先,企业通过技术知识搜索获得互补性资源,缩小与外部知识源的知识势差,形成针对产品或技术流程的突发性创意及获取解决问题的经验。其次,企业从外部知识网络中搜索到的分散、无序的技术知识碎片难以发挥作用,而将不同性质、形式的部件知识以新形式重新融合与连接后,容易形成新概念或新工艺。外部资源能否发挥作用取决于问题特征、所需知识特征以及外部源特征[21]。比如,对于全新的问题,如果还沿用老套路和原有的认知框架将会带来风险[16];如果任务很容易模块化,而外部环境中存在大量有用的知识,借助外部大数据环境是条高效的途径。
图1 概念模型
IT外包项目特征、所需知识以及外部源等促使项目组通过外部搜索,从大数据环境中获取帮助。IT外包项目绩效主要包括项目完成质量、进度和成本[22-23]。易得性较高的大数据环境能够给项目提供大量多样化、低成本和更新快的信息与知识资源。IT外包项目涉及到的技术知识、业务知识、文化知识种类繁多且更新快,企业不可能掌握那么全面,但在互联网上存在大量可用的资源。由此可知,外部大数据环境对IT接包企业十分重要。在易得性较高的大数据环境下,IT外包项目组人员可以利用搜索引擎、百科、论坛社区、开源软件社区等搜索所需知识。如要获取开源软件程序,通过在专业社区提问可获得高技能专业人士帮助,通过积累知识提高核心竞争力等,从而既保证了项目完成质量,又节省了成本,确保了进度。综上得出以下假设:
H1:大数据易得性提高接包企业项目绩效。
1.2.2 大数据冗杂性与绩效
由于更加依赖模块化知识,IT外包企业与外部大数据环境关系密切。IT外包项目特征、所需知识特征以及外部源特征等都促使项目组进行外部搜索,以从大数据环境中获取帮助。但是大数据有其两面性:一方面,大数据带来了大量可用信息;另一方面,数据的冗杂和混乱产生大量无用信息,而企业希望以最少的时间获得更多、更准确的信息[24]。低质量的信息增加了模糊性,模糊性指的是不缺少信息但因信息杂乱造成混淆[25]。因此,能否在保证外部知识多样性的同时,减少重复、无关、低质量的知识,是企业不得不考虑的一个问题。Hazen等[24]从5个方面解释数据质量,即精确性、及时性、一致性、完备性和易识别性。准确性描述的是数据中不出现错误的概率,及时性是指数据实时更新的程度,一致性描述的是多种数据来源的无差异性,完备性描述的是数据对一个事物描述的完整程度,易识别性描述的是数据简明扼要并容易被理解的程度。最近一项调查显示,1/5的高管将数据质量问题列为其采纳数据驱动战略的首要障碍[4]。外部数据质量与IT外包项目绩效有直接关系,高质量的数据和知识资源能使公司保持竞争力。低劣的数据质量一方面会造成有形损失,对于一般企业,低劣数据造成的损失占总收入的比例可高达8%~12%,对于服务型企业可能增加至40%~60%。另一方面,也会造成无形损失,如工作满意度、决策质量、在组织内和组织间传播不信任气氛[26]。
因此,当IT外包项目团队向外搜索知识时,如果大数据环境的数据质量较低,则对项目绩效有抑制作用。首先,当项目团队面临低质量大数据时,搜索成本和辨别成本增加,时间和精力被浪费。其次,低质量数据增加了对问题理解的模糊性,使原本清晰的认知变得模棱两可,造成项目团队交流的额外开支,甚至导致项目延期。除此之外,使大数据应用变得困难,在提取低质量数据后需要进行“清洗”,以保证数据质量。比如在获取开源软件程序时,文档缺失将很难维护和扩展项目,较差的兼容性导致需投入大量时间和资金在人员培训与发展上。因此,数据的不准确、不完整性造成资源浪费和生产力损失。第三,获取的知识或其它数据资源缺乏完整性,使项目组成员难以理清内在逻辑关系,简单拼凑往往难以达到项目要求且产生次优结果。因此,研究提出如下假设:
H2:大数据冗杂性降低接包企业项目绩效。
1.2.3 功能组合式开发策略的调节作用
根据资源编排理论,资源编排是指企业通过不同方式有效组合资源、产生多样化的结果。该理论强调资源对绩效的作用不应仅关注拥有多少有价值的资源,还应关注企业如何调配、组合利用资源,不同编排方式产生的效果具有一定差异。资源编排方式在资源与绩效关系间起调节作用,影响资源优势的发挥。当采用功能组合式开发策略时,项目团队具有强烈的利用现成大数据资源的意愿。功能组合式开发是指根据不同需求,对现有软件功能重新组合,使产品更有创意和创造更多功能。根据Henderson和Clark[16]、Carnes等[14]的观点,组合式开发策略是在产品开发过程中对企业现有知识的重新配置,采用该方式的项目需要大量现成资源。当大数据环境中的资源易得性较高时,企业拥有的资源池也较大。当组合策略程度较低时,这种因资源多样性带来的优势难以充分发挥;当组合策略程度较高时,项目开发团队更加擅长通过组合不同资源来实现绩效。此时,大数据环境带来的多样性、数量资源优势更容易被释放。因此,当大数据环境中存在大量项目所需的知识或其它数据资源(如开源程序、公开代码、百科知识)时,将帮助开发团队有效地将外部资源用到项目中,从而从大数据环境中获益。
当大数据环境质量较差时,采用功能组合式开发策略将使企业绩效变差。这是因为功能组合式开发策略要求现有资源能有效组合,如果从外部大数据环境中获取的知识和其它数据资源质量较差,如资源陈旧过时,或者不完整,以及不能与现有资源兼容,即大数据环境冗杂性较高,将影响资源编排效果,降低项目完成质量。综上得出如下假设:
H3a:当项目采用功能组合式开发时,大数据易得性对项目绩效的正向作用增强;
H3b:当项目采用功能组合式开发时,大数据冗杂性对项目绩效的负向作用增强。
1.2.4 专项突破式开发策略的调节作用
专项突破是指对某个专项技术的核心概念重新设计,或者对专项技术的内部逻辑作出根本性改变[16]。在IT外包背景下,专项突破式开发策略主要是指集中资源突破技术专项,选择单个元件或模块作为突破口,集中在某一专项技术领域远超过竞争对手。专项突破式开发策略需要的知识和能力不同于功能组合式开发策略的知识与能力,该方式需要掌握某个组件的核心知识、内部逻辑、根本原理,要求对核心概念有系统而深入的理解,需要更为详尽、有质量的数据源。当项目采用专项突破式开发时,大数据易得性对项目绩效的正向作用减弱,即较高的大数据易得性并不能给专项突破式项目带来更高绩效。这是因为专项突破需要系统化、有深度的知识,而大数据环境中尽管存在大量易于获得的知识和其它资源,但这些知识和资源常常是碎片化的,知识深度不足。因此,项目开发所需知识和大数据环境供给的知识间出现了不适配,这种信息供应和需求的不适配会损害绩效[25]。当采用专项突破策略且处于易得性较高的大数据环境时,项目团队有可能放弃对优质资源的追求而得到次优结果,因此并没有实现真正的突破。
当IT外包项目采用专项突破式开发策略时,大数据冗杂性对项目绩效的负向作用将会减弱。当采用专项突破式开发策略时,项目团队利用外部大数据资源的机会较少。专项突破开发所需知识的专业化程度更高、知识深度更大,与特定情境的关系更加密切[27]。因此,项目团队会投入一定精力在小组讨论、内部消化、团队攻坚上[28]。当采用专项突破式开发时,即使面对的外部大数据资源冗杂性较高,对项目开发的影响也不大。这是因为虽然大数据冗杂性较高,但是由于利用机会少而避免了冗杂性对项目绩效的负面影响。综上得出以下假设:
H4a:当项目采用专项突破式开发时,大数据易得性对项目绩效的正向作用减弱;
H4b:当项目采用专项突破式开发时,大数据冗杂性对项目绩效的负向作用减弱。
2.1 样本选择与数据收集
本文采用问卷调查方法验证假设。问卷主要参考了英文文献中较为成熟的量表,在缺乏成熟量表时以变量概念和相关文献为基础,设计了大数据测量题项。在文献总结以及专家咨询的基础上,设计了调查问卷的英文版;然后请精通英文的管理学教授把问卷翻译成中文,并与4位长期从事IT外包业务的专家进行讨论;问卷设计好后选取10位项目经理进行预调研,根据预调研的反馈确定问卷最终版;最后请一位在美国工作的华人教授把中文问卷翻译为英文,并与原来的英文问卷进行对比,以保证中英文对应和交叉语言的同等性。
本研究选择西安、大连、成都、深圳这4个国家级服务外包示范城市,根据4个城市服务外包协会提供的企业列表,从中随机选取120家企业作为样本。研究以项目为单位,问卷调研以项目层面为主,将项目经理作为调研对象,让每个人就其最近交付的IT软件外包项目情况填写。同时,为了避免同源误差,要求每一个项目团队的一位成员填写关于项目绩效等方面的问题。 本文采用面对面填写问卷方式,以避免误解、应付差事等因素带来的不确定性。在120家企业中最终接受调研的有44家,每一家公司根据要求挑选出合适的项目经理若干名,最终收回问卷202份,剔除关键信息填写不完整和回答雷同较多的无效问卷7份,有效问卷195份,样本基本特征如表1所示。从表1可以看出,样本企业较为成熟(企业年龄大于5的占81.8%),规模上符合软件外包企业特征,即以中小企业为主;调研项目均为软件外包项目,其中,发包方为日本的占40.0%、美国的占23.1%、中国的占29.8%、其它占7.1%,业务类型几乎涵盖软件开发的各个方面。通过样本特征描述可以发现,本研究收集的样本数据完全符合研究需要。本次调研的有效问卷回收率为 36.7%,为了检验未回收误差对抽样有效性的威胁,根据Armstrong和Overton的建议,采用T检验对回收样本和未回收样本的企业规模、 企业年龄进行对比。T检验结果显示,两组样本在企业规模和企业年龄方面不存在显著差异,说明未回收偏差不会给抽样有效性带来严重威胁。
表1 样本特征

特征频率(%)特征频率(%)(一)企业特征1.企业年龄2.企业规模≤518.2≤5031.86-1025.051-10011.411-1531.8101-20020.516-2015.9201-50015.8≥219.1≥50120.5(二)项目特征1.项目发包国类别2.业务类型日本40.0定制开发62.6美国23.1系统设计19.5中国29.8模块开发27.2其它国家/地区7.1Coding20.0测试28.2维护/托管15.4其它1.5
2.2 变量测量
通过文献查阅、专家讨论、深度访谈等方式,本文采用李克特5级量表测量变量,问卷应试者通过自己的感知来回答。本文变量测量尽量采用IT外包中已有量表,如果没有,则采用经典文献中的测量量表,同时,根据IT外包背景进行适当修改。表2描述了各变量的测量题项。
(1)项目绩效:参照文献[22][23],本文采用4个指标测量接包企业的项目绩效:①我们交付的服务非常符合发包方的期望;②我们按合同规定进度及时交付;③我们提供的服务质量很高;④总体上看,客户对本项目非常满意。
(2)大数据易得性:参考Wamba等[2]、Hazen等[24]的研究,本文设计了4个指标来测量大数据易得性:①外部环境中可获取的数据和信息越来越多;②数据和信息数量的增长越来越快;③数据和信息的单位存储量越来越大;④与任何事物相关的信息传播速度很快。
(3)大数据冗杂性:参考Wamba等[2]、Hazen等[24]的研究,本文设计4个指标来测量大数据冗杂性: ①很多数据和信息错误较多,甚至相互冲突;②很多知识和信息真假难辨;③很多知识和信息质量不高;④很多知识和信息难以利用。
(4)功能组合策略:参照文献[13][16],结合IT外包背景,本文采用4个指标来测量功能组合策略:①根据不同需求对软件功能进行组合;②在软件开发方面强调功能组合的多样性;③开发软件时通过功能组合,使产品更有创意;④通过整合现有技术,创造更多功能。
(5)专项突破策略:参照文献[16][28],结合IT外包背景,本文采用3个指标测量专项突破策略:①强调集中资源,突破技术专项;②强调选择单个元件或模块作为突破口;③集中在某一专项技术领域远超竞争对手。
(6)控制变量:选取企业年龄、企业规模、发包国家、发包方支持作为控制变量。企业年龄用企业年限的自然对数转换值表征,企业规模则根据埃森哲、IDC等国际著名咨询公司的标准来分类,用1、2、3、4分别代表小公司、中等公司、大公司、特大型公司,发包国家用虚拟变量0、1来表示日本、美国、中国等,发包方支持用李克特5级量表测量。
2.3 信度、效度检验
本文采用Alpha系数进行信度检验,检验结果如表2所示。一般来说,衡量同一要素全部指标的Alpha系数值超过0.7就是合适的,而对于尚未验证的变量,其Alpha系数值大于0.65即可。结果显示,项目绩效、发包方支持、大数据易得性、大数据冗杂性、功能组合式开发和专项突破式开发的Alpha系数值都大于0.7,说明问卷具有良好信度,达到研究要求。在收敛效度方面,表2中各个指标的因子载荷都大于0.75,AVE值都大于0.6,根据Fornell和Larcker提出的标准,测量的收敛效度较好。为检验变量的区别效度,研究将AVE开方值与相关系数进行比较,表3对角线上的数字表示AVE的开方值,该数值均大于所在行和所在列的相关系数,说明变量间有较好的区别效度。
表2 变量测量及信度效度检验
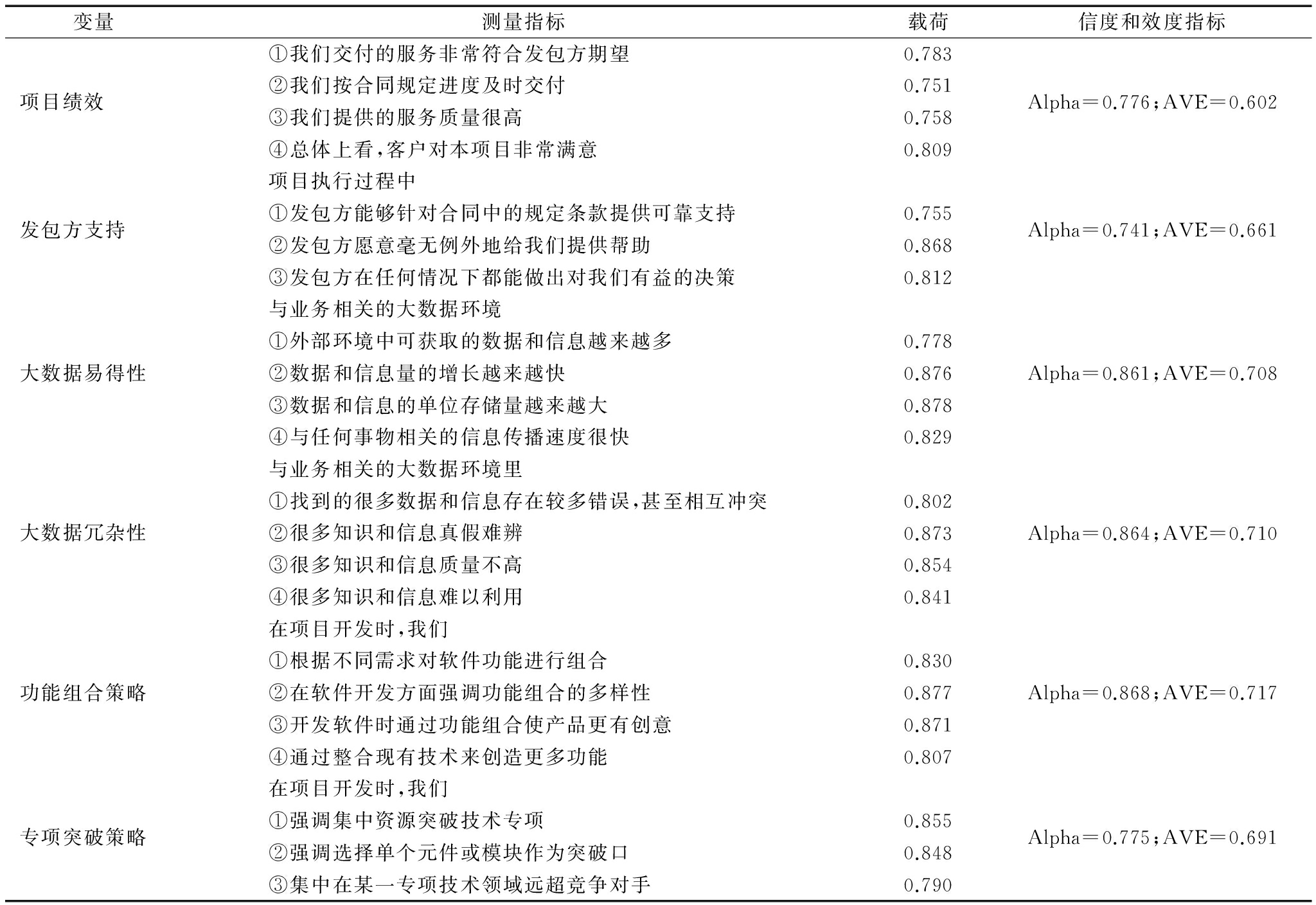
变量测量指标载荷信度和效度指标①我们交付的服务非常符合发包方期望0.783项目绩效②我们按合同规定进度及时交付0.751Alpha=0.776;AVE=0.602③我们提供的服务质量很高0.758④总体上看,客户对本项目非常满意0.809项目执行过程中发包方支持①发包方能够针对合同中的规定条款提供可靠支持0.755Alpha=0.741;AVE=0.661②发包方愿意毫无例外地给我们提供帮助0.868③发包方在任何情况下都能做出对我们有益的决策0.812与业务相关的大数据环境①外部环境中可获取的数据和信息越来越多0.778大数据易得性②数据和信息量的增长越来越快0.876Alpha=0.861;AVE=0.708③数据和信息的单位存储量越来越大0.878④与任何事物相关的信息传播速度很快0.829与业务相关的大数据环境里①找到的很多数据和信息存在较多错误,甚至相互冲突0.802大数据冗杂性②很多知识和信息真假难辨0.873Alpha=0.864;AVE=0.710③很多知识和信息质量不高0.854④很多知识和信息难以利用0.841在项目开发时,我们①根据不同需求对软件功能进行组合0.830功能组合策略②在软件开发方面强调功能组合的多样性0.877Alpha=0.868;AVE=0.717③开发软件时通过功能组合使产品更有创意0.871④通过整合现有技术来创造更多功能0.807在项目开发时,我们专项突破策略①强调集中资源突破技术专项0.855Alpha=0.775;AVE=0.691②强调选择单个元件或模块作为突破口0.848③集中在某一专项技术领域远超竞争对手0.790
表3 描述性统计分析和相关系数(N=180)
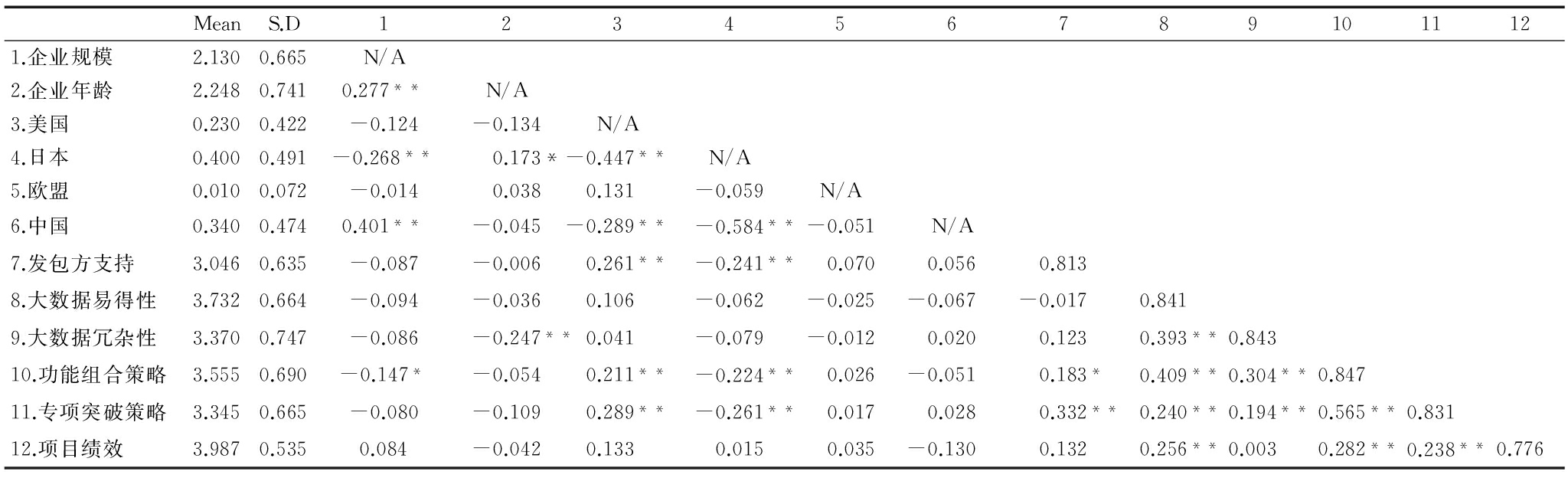
MeanS.D1234567891011121.企业规模2.1300.665N/A2.企业年龄2.2480.7410.277**N/A3.美国0.2300.422-0.124-0.134N/A4.日本0.4000.491-0.268**0.173*-0.447**N/A5.欧盟0.0100.072-0.0140.0380.131-0.059N/A6.中国0.3400.4740.401**-0.045-0.289**-0.584**-0.051N/A7.发包方支持3.0460.635-0.087-0.0060.261**-0.241**0.0700.0560.8138.大数据易得性3.7320.664-0.094-0.0360.106-0.062-0.025-0.067-0.0170.8419.大数据冗杂性3.3700.747-0.086-0.247**0.041-0.079-0.0120.0200.1230.393**0.84310.功能组合策略3.5550.690-0.147*-0.0540.211**-0.224**0.026-0.0510.183*0.409**0.304**0.84711.专项突破策略3.3450.665-0.080-0.1090.289**-0.261**0.0170.0280.332**0.240**0.194**0.565**0.83112.项目绩效3.9870.5350.084-0.0420.1330.0150.035-0.1300.1320.256**0.0030.282**0.238**0.776
注:*表示在0.05水平显著(2-tailed),**表示在0.01水平显著(2-tailed);N=195,斜对角线上为AVE的开方值
2.4 假设验证与结果
表3给出了描述性统计分析和Pearson相关分析。结果显示,变量间的相关系数没有高于0.65的阈值,表明数据结果受到多重共线性威胁的可能性较小。
采用分步回归分析方法。首先,检验企业规模、企业年龄、发包国家、发包方支持等控制变量对项目绩效的影响(模型1),此步骤便于观察回归模型中加入研究变量后R值的变化。在此基础上,为了验证大数据环境对项目绩效的影响,将大数据易得性、大数据冗杂性加入模型2中。结果显示,大数据易得性的回归系数显著为正(0.333,p<0.001),大数据冗杂性的回归系数显著为负(-0.160,p<0.05)。这说明当项目团队所处的大数据环境中有大量易于获取的信息和知识时,会显著促进接包企业项目绩效提升。而当项目团队面对的数据环境冗杂性较高时,会显著阻碍项目绩效提升。因此,假设H1和H2得到支持。
为了检验两种项目开发策略的调节作用,在模型3中加入了调节变量及其交互项,在进行回归分析前对交互项变量进行均值中心化处理。结果显示,大数据易得性与组合式开发交互项的回归系数显著为正(0.252,p<0.05,见图2(a)),大数据冗杂性与组合式开发交互项的回归系数为负但不显著(-0.049,见图2(b))。因此,假设H3a得到支持,假设H3b未获支持。大数据易得性与突破式开发交互项的回归系数显著为负(-0.200,p<0.05,见图2(c)),大数据冗杂性与突破式开发交互项的回归系数为正但不显著(0.027,见图2(d))。因此,假设H4a得到支持,假设H4b未获支持。
3.1 理论贡献
(1)研究发现,大数据环境的不同维度对IT接包项目绩效有不同影响。大数据易得性显著提高IT外包项目绩效,大数据冗杂性显著降低IT外包项目绩效。这表明尽管大数据已经成为重要的IT外包企业环境维度,但大数据环境有其两面性,即易得性和冗杂性。一方面,大数据的量很大,易于获得;另一方面,大数据的冗杂性也是不争的事实。通过实证研究发现,并非所有的企业都能从外部大数据中获益,这与所处的大数据环境密切相关。当所处的大数据环境中数据资源易得性较高时,能够促进项目绩效提升,但当所处的环境中数据冗杂、难以使用时,会降低项目绩效。这一结论既弥补了大数据实证研究的缺乏,又丰富了现有研究文献[5,24]。
表4 回归分析结果(N=195)
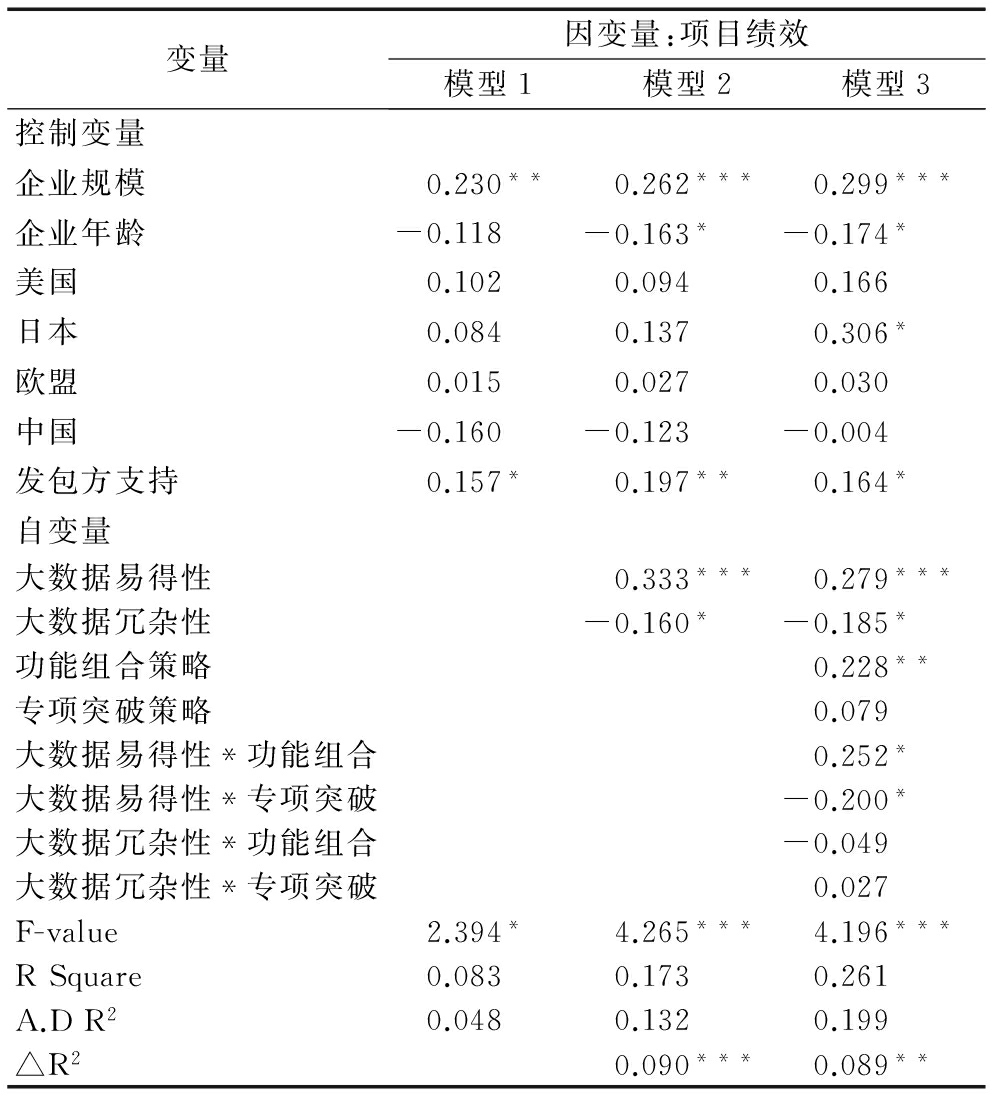
变量因变量:项目绩效模型1模型2模型3控制变量企业规模0.230**0.262***0.299***企业年龄-0.118-0.163*-0.174*美国0.1020.0940.166日本0.0840.1370.306*欧盟0.0150.0270.030中国-0.160-0.123-0.004发包方支持0.157*0.197**0.164*自变量大数据易得性0.333***0.279***大数据冗杂性-0.160*-0.185*功能组合策略0.228**专项突破策略0.079大数据易得性*功能组合0.252*大数据易得性*专项突破-0.200*大数据冗杂性*功能组合-0.049大数据冗杂性*专项突破0.027F-value2.394*4.265***4.196***RSquare0.0830.1730.261A.DR20.0480.1320.199△R20.090***0.089**
注:+表示在0.1水平下显著,*表示在0.05水平下显著,**表示在0.01水平下显著,***表示在0.001水平下显著
(2)本文检验了两种项目开发策略的调节作用,指出了利用外部大数据环境的边界条件。实证结果显示,组合式开发策略增强了大数据易得性对项目绩效的正向作用,专项突破式开发策略削弱了大数据易得性对项目绩效的正向作用。本文基于资源编排理论认为,采用不同资源编排方式的资源利用效果存在差异,功能组合和专项突破是IT外包项目开发中常用的两种资源编排策略。功能组合式开发策略需要大量现成资源,因而项目能够更好地利用大量易得的大数据。专项突破式开发策略需要质量更优而不是体量更大的资源,因而当采用专项突破式开发时,项目从大量易得数据中获益的优势被削弱。这一研究结论指出了利用大数据的情景条件,揭示了大数据的作用发挥与项目开发策略有关。本文还将Henderson和Clark[16]的组合式创新和专项式创新构念应用于IT外包并进行了操作化定义,设计了测量量表。除此之外,将Sirmon、Hitt等[12]在资源基础理论框架下提出的资源编排理论应用于大数据资源利用研究,为资源编排文献以及大数据使用边界条件提供了新的洞察方向。
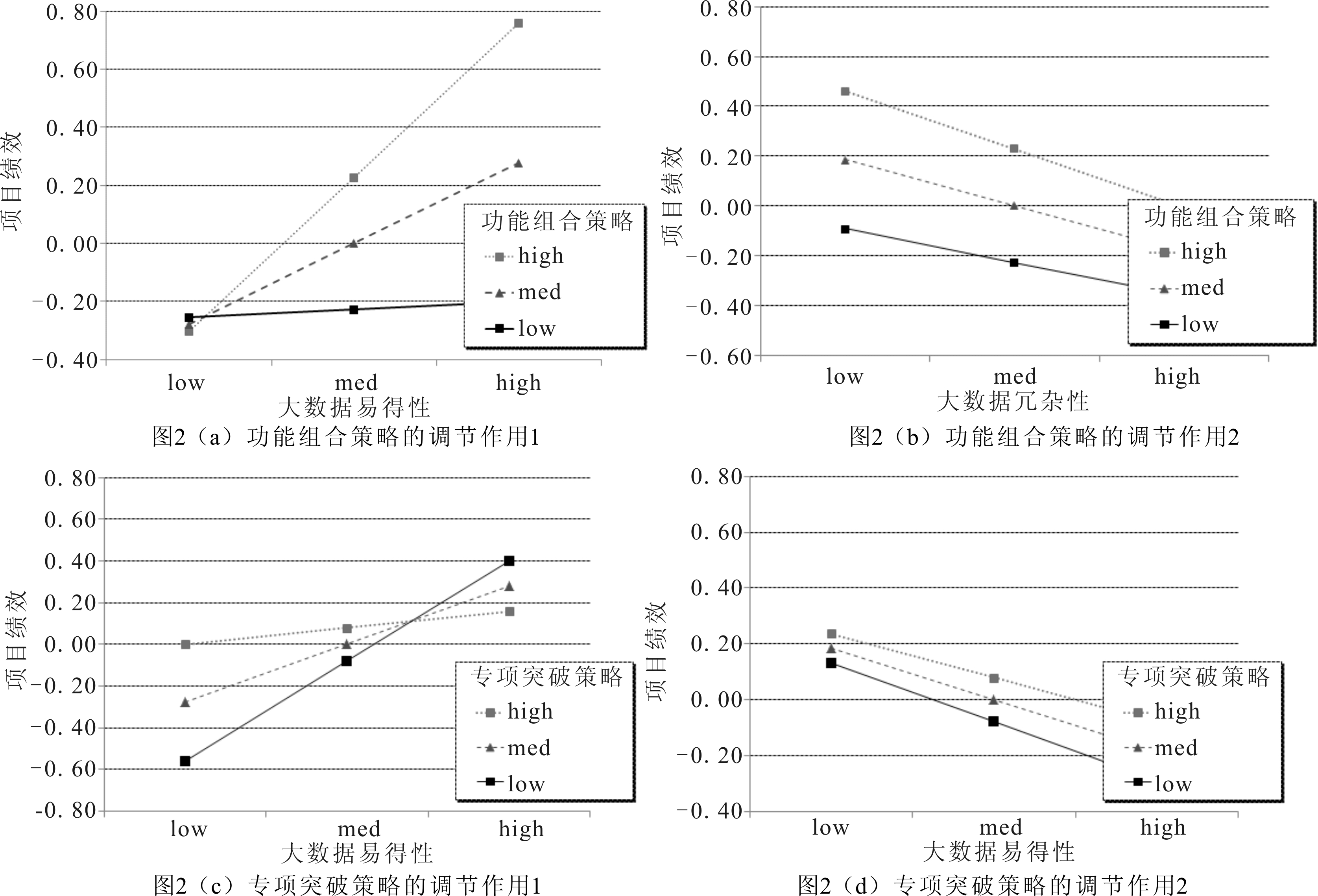
(3)虽然假设H3b和H4b未获支持,但也有其理论意义。假设H3b认为功能组合式开发策略增大了大数据冗杂性对项目绩效的负作用,假设H4b认为专项突破式开发策略减弱了大数据冗杂性对项目绩效的负作用。实证检验结果表明,两种策略对大数据冗杂性与绩效关系无显著调节作用。这进一步说明大数据冗杂性对项目绩效的负向作用是比较鲁棒的,且很难通过改变资源编排方式来避免。企业利用大数据环境既包括如何开发利用大数据,又包括筛选甄别大数据。功能组合式开发策略和专项突破式开发策略的重点在于对大数据资源的开发利用,而要克服大数据冗杂性的负面作用需要良好的筛选甄别机制。因此,后续研究中将重点关注如何筛选甄别外部大数据。同时,企业应该在实践中避免陷入无效的数据环境中。
3.2 管理建议
(1)大数据与IT外包项目绩效的直接效应表明,外部大数据是IT外包企业必须重视的重要来源,所处的大数据环境不同将对项目绩效产生差异化影响。当所处的大数据环境易得性较高时,绩效将得到促进,当所处的大数据环境质量较差时,绩效将会降低。因而,企业应该想办法使自己处于易得性较高、质量较优的大数据环境中。比如,一方面可以鼓励有经验的员工将好的数据源在企业中分享,避免其他员工陷入低质量的数据环境中,同时,注意平时的积累和筛选,在企业内部建立优质资源目录。另一方面,可以投入资金,赞助网上专业知识社区或者开源软件社区等,以提高外部大数据的相关性、及时性、完整性和易识别性。
(2)开发策略调节了大数据环境对IT外包项目绩效的影响。在实践中,企业应该采用合适的项目开发策略,不同的开发策略使大数据环境发挥不同作用。当项目有大量可用的大数据资源时,采取功能组合方式将会促进绩效提升,此时应该主动利用外部大数据环境;当项目采用突破式开发策略时,应该以内部学习、技术攻关为主,不宜将注意力过多地放在外部大数据环境上,因为其会削弱IT外包项目绩效。
3.3 未来研究与不足
尽管本研究具有一定理论创新性和实践价值,但也存在一定局限性。首先,大数据特征是所谓的4V(Volume,Variety,Velocity,Value),即大量、多样、快速、价值,后续研究可以验证多样、快速等维度对绩效的影响。其次,本文检验了大数据对项目绩效的影响。文中的项目绩效主要是指项目完成情况,后续研究可以考虑大数据环境对合作关系、知识获取、创新等的影响。再次,本文检验了项目开发策略的调节作用,其它调节变量也值得研究,尤其是对大数据冗杂性与绩效关系有显著调节作用的变量。最后,本文的实证数据来自于IT外包行业,与IT外包差异较大的其它行业在应用本研究成果时需谨慎对待。
参考文献:
[1] CHEN C L P,ZHANG C Y.Data-intensive applications,challenges,techniques and technologies:a survey on Big Data[J].Information Sciences,2014,275:314-347.
[2] WAMBA S F,AKTER S,EDWARDS A,et al.How "big data" can make big impact:findings from a systematic review and a longitudinal case study[J].International Journal of Production Economics,2015,165:234-246.
[3] HASHEM IAT,YAQOOB I,ANUAR N B,et al.The rise of "big data" on cloud computing:review and open research issues[J].Information Systems,2015,47:98-115.
[4] LAVALLE S,LESSER E,SHOCKLEY R,et al.Big data,analytics and the path from insights to value[J].MIT Sloan Management Review,2011,52(2):21.
[5] MCAFEE A,BRYNJOLFSSON E.Big data:the management revolution[J].Harvard Business Review,2012,90(10):61-67.
[6] 徐宗本,冯芷艳,郭迅华,等.大数据驱动的管理与决策前沿课题[J].管理世界,2014 (11):158-163.
[7] BARNEY J.Firm resources and sustained competitive advantage[J].Journal of Management,1991,17(1):99-120.
[8] BARNEY J B.Resource-based theories of competitive advantage:a ten-year retrospective on the resource-based view[J].Journal of Management,2001,27(6):643-650.
[9] SU N. Internationalization strategies of Chinese it service suppliers[J].MIS Quarterly,2013,37(1) :175-200.
[10] MORGAN L,FINNEGAN P.Beyond free software:an exploration of business value of strategic open source[J].The Journal of Strategic Information Systems,2014,23(3):226-238.
[11] LIPPMAN S A,RUMELT R P.A bargaining perspective on resource advantage[J].Strategic Management Journal,2003,24(11):1069-1086.
[12] SIRMON D G,HITT M A,IRELAND R D,et al.Resource orchestration to create competitive advantage breadth,depth,and life cycle effects[J].Journal of Management,2011,37(5):1390-1412.
[13] CARNABUCI G,OPERTI E.Where do firms' recombinant capabilities come from intraorganizational networks,knowledge,and firms' ability to innovate through technological recombination[J].Strategic Management Journal,2013,34(13):1591-1613.
[14] CARNES C M,CHIRICO F,HITT M A,et al.Resource orchestration for innovation:structuring and bundling resources in growth-and maturity-Stage firms[J].Long Range Planning,2016.
[15] CHIRICO F,SIRMON D G,SCIASCIA S,et al.Resource orchestration in family firms:investigating how entrepreneurial orientation,generational involvement,and participative strategy affect performance[J].Strategic Entrepreneurship Journal,2011,5(4):307-326.
[16] HENDERSON R M,CLARK K B.Architectural innovation:the reconfiguration of existing product technologies and the failure of established firms[J].Administrative Science Quarterly,1990:9-30.
[17] PARK J K,RO Y K.Product architectures and sourcing decisions their impact on performance[J].Journal of Management,2013,39(3):814-846.
[18] HOFMAN E,HALMAN J I M,VAN LOOY B.Do design rules facilitate or complicate architectural innovation in innovation alliance networks [J].Research Policy,2016,45(7):1436-1448.
[19] MEHTA N,BHARADWAJ A.Knowledge integration in outsourced software development:the role of sentry and guard processes[J].Journal of Management Information Systems,2015,32(1):82-115.
[20] WEST J,BOGERS M.Leveraging external sources of innovation:a review of research on open innovation[J].Journal of Product Innovation Management,2014,31(4):814-831.
[21] AFUAH A,TUCCI C L.Crowdsourcing as a solution to distant search[J].Academy of Management Review,2012,37(3):355-375.
[22] MAO J Y,LEE J N,DENG C P.Vendors' perspectives on trust and control in offshore information systems outsourcing[J].Information & Management,2008,45(7):482-492.
[23] LANGER N,SLAUGHTER S A,MUKHOPADHYAY T.Project managers' practical intelligence and project performance in software offshore outsourcing:a field study [J].Information Systems Research,2014,25(2):364-384.
[24] HAZEN B T,BOONE C A,EZELL J D,et al.Data quality for data science,predictive analytics,and big data in supply chain management:an introduction to the problem and suggestions for research and applications[J].International Journal of Production Economics,2014,154:72-80.
[25] DAFT R L,LENGEL R H.Organizational information requirements,media richness and structural design[J].Management Science,1986,32(5):554-571.
[26] BATINI C,CAPPIELLO C,FRANCALANCI C,et al.Methodologies for data quality assessment and improvement[J].ACM Computing Surveys (CSUR),2009,41(3):16.
[27] KAPLAN S,VAKILI K.The double-edged sword of recombination in breakthrough innovation[J].Strategic Management Journal,2015,36(10):1435-1457.
[28] CARLO J L,LYYTINEN K,ROSE G M.A knowledge-based model of radical innovation in small software firms[J].MIS Quarterly,2012,36(3):865-895.
(责任编辑:胡俊健)
Big Data Environment and IT Outsourcing Vendor's Project Performance: A Resource Orchestration Theory Perspective
Abstract:IT outsourcing industry is knowledge intensive. The external big data environment is becoming a potential knowledge source of vendors. However, is the big data environment really promoting the vendors' IT outsourcing project performance? How should project benefit from it? There is absence in extant literatures on these issues. This study based on the resource orchestration theory, explores the direct impacts of the data availability and poor quality of big data on IT outsourcing project performance, and also tests the moderating effects of function recombination development and modular technology breakthrough development strategies.195 IT outsourcing project data is collected to examine 6 hypotheses. The results show that big data availability significantly increases outsourcing project performance, but poor quality of big data significantly reduces project performance. Function recombination development positively but modular technology breakthrough development strategy negatively moderates the relationship between the big data availability and project performance. Both of the two development strategies have non-significant moderating effect on the relationship between the poor quality of big data and project performance.
Key Words:Availability of Big Data; Muss of Big Data; Information Technology Outsourcing; Function Recombination Development Strategy; Modular Technology Breakthrough Development Strategy
收稿日期:2016-11-08
基金项目:国家自然科学基金重点项目(71132006);国家自然科学基金面上项目 (71572142); 教育部人文社会科学研究青年基金项目 (11YJC630040)
DOI:10.6049/kjjbydc.2016090537
中图分类号:F490.6
文献标识码:A
文章编号:1001-7348(2017)04-0023-08