表1 西安某高校大学心理状况调查的语义差异

等级从无轻度中度偏重严重调查者设计值01234受访者实际值0.52±0.261.25±0.21.96±0.162.74±0.213.82±0.28
摘 要:李克特式量表可以定量地对指标进行评价,常常被用在包括区域科技创新环境在内的各种排名与其它统计分析中。李克特式量表在应用时首先设置不同选项(等级),要求受访者从中选择比较符合要求的一项,最后通过调查者赋予不同等级的选项以不同分值,进一步定量地计算所有受访者对该项测量指标的总体评价。然而,在李克特式量表中,问卷设计者主观赋予的不同等级分值与受访者认为的赋值可能存在一定的语义差异,从而导致测量结果在有些情况下不能充分反映受访者的真实态度,进而影响统计分析结果的可靠性。首先对语义差异进行了论述,然后通过李克特量表对区域科技创新环境排名的具体应用中语义差异导致的有效性问题进行了算例分析。此后,采用数值分析和数理推理方法,分析了确保调查结果可靠性的语义差异范围,并且给出了降低语义差异对李克特式量表排名影响的等级分值赋值方法。最后,通过一个实例分析了所探讨的问题并演练了相应理论结论的应用过程。
关键词:李克特式量表;语义差异;科学测量
李克特式量表具有操作性强、效度和信度高及分析性强等特点,成为最常用的主观评价工具并应用于不同种类的统计分析中,如回归分析[1]、因子分析[2]、主成分分析[3]、方差分析[4]等。李克特式量表能够通过快速直观地获取受测者对某主题的认同程度并对其进行量化。因此,其调查结果植入到其它统计分析方法中能够展开进一步的统计分析。所以,李克特量表在不同产业统计分析中都有广泛应用[5]。例如,在地区科技创新排名中,王爽等[6]采用李克特式量表对海淀区科技创新型企业发展能力进行了评价,俞立平等[7]分析了不同国家大学排名中李克特式量表的指标体系,而董彦斌[8]、陈文军[9]、曹梦[10]和段小薇[11]等采用李克特量表计算了不同地区的科技创新能力和环境评价指标,并根据得到的数据进行了不同地区排名。
李克特式量表等级法在理论上常被称为要素评估法或因素评分法,它起源于Likert[12]提出的“要求受访者在多项选择中给出一项选择”的方法(如“从没有”,“很少”,“有时候”,“经常”,“一直”),通常称为李克特式量表。李克特式量表在应用时,首先将评价目标分解成若干指标并赋予权重,对每个指标设计一个区分等级的量表,然后,根据量表对受访者作调查,所得调查数据通过加权汇总后即得到评价目标的得分。基于Likert[13]的量表设计理论,其他学者针对不同问题,给出了不同的李克特式等级量表,如四点法[13]、五点法[14]、七点法[15]和十点法[16]等,可以针对不同调查对象和测量目标选择适当的量表等级[17]。
采用李克特式量表进行评价时的重要一步是对量表的等级赋值。例如,在5等级量表中,可以将科技创新环境设置为“非常好”、“好”、“一般”、“差”、“非常差”,分别赋值-50、-25、0、25、50分。原则上,不同等级所赋分值应该与该等级的语义相对应,如“差”程度介于“一般”(0分)与“非常差”(50分)的正中间。因此,赋值为两者中间值25分。然而,对同一个等级,调查者的赋值(设计值)与受访者的赋值(真实值)可能不一致,两者的差异称为“语义差异”[18]。目前,一些统计学相关文献已经开始关注调查者与受访者语义差异问题。为了直观地表达语义差异,李亚红[19]在西安某高校做了关于大学生精神状况的随机调查,该项调查显示了受访者对不同等级的语义差异(见表1)。
表1 西安某高校大学心理状况调查的语义差异
等级从无轻度中度偏重严重调查者设计值01234受访者实际值0.52±0.261.25±0.21.96±0.162.74±0.213.82±0.28
由于调查者按照设计值而不是受访者实际分值计算指标得分,因此,不能反映受访者的实际分值。一些学者从案例研究中发现[20],由于李克特式量表要求受访者必须明确地从问卷中选择适当的等级选项,问卷设计值与受访者对不同等级的语义理解不可避免地存在或大或小的差异,因此,语义差异在测量中广泛存在。由于对同等级的赋值具有明显的主观性,这种量化方式在很多情况下因调查者赋值与受访者赋值不一致,会导致在实际应用中可能出现调查结果错误[21]。简明和魏泉红[22]举例说明了语义差异的存在性,惠新(2009)也举例发现语义差异在测量中带来的偏差。遗憾的是,现尚无文献定量分析两者语义差异对测量结果和测量结论的影响[23],在特定的应用领域(如本文所研究的科技创新能力与环境评价的案例)结果的正确性面临很大不确定性。针对此,本文首先以一个科技创新评价案例明确地说明语义差异带来的影响;然后,定量分析多大程度的语义差异不会导致测量结果失真、多大程度的语义差异将会导致测量结果错误,最后,提出有效降低语义差异导致科技创新环境评价排名误差的步骤。
使用李克特式量表对受访者进行调查时,往往经过指标设计、等级与刻度设计、计算得分3个基本步骤即可得到受访者的态度情况。例如,2016年某省委托第三方调查机构对下属市级单位辖区科技创新能力进行了调查和排名,调查时请企业受访者对自身科技发展过程中所处发展环境作出评价,即从“十分满意,满意,一般,不满意,十分不满意”中选择符合其观点的一项。得到受访结果后,第三方调查机构将各个选项赋予一定分值,十分满意为100分,满意80分,一般60分,不满意40分,十分不满意20分(见表2),即最高分为100分、最低分为0分,不同选项之间分值之差分别为40、20、20和20分(如“十分不满意”与“不满意”分值差40分)。
不同辖区企业受访者对所处科技创新环境的评价如表2所示,如A市辖区成功调查了751人,其中,从“十分不满意”到“十分满意”5个等级评价的企业数分别为91、75、256、171和158家。在通过了信度效度检验后,根据调查者对每个等级的赋分,可以计算得到A市企业受访者对科技创新环境的评价平均得分S:

×[0,40,60,80,100]T=63.7
(1)
对比表2和表3可以发现,各个辖区科技创新环境的平均得分均有所变化,如A市的得分由63.7分变为60.7分。同时,在表2中A市得分低于B市,然而在表3中A市得分高于B市。显然,由于表3显示了企业受访者的等级语义,因此,表3得到的排名能够反映真实的企业受访者满意度程度和排名。
同理,可计算得到其它辖区企业受访者(如B市)的科技创新环境满意度,并根据平均得分高低对不同市政府进行排名。然而,式(1)表明科技创新环境满意度既与受访者的选择有关,也与调查者的等级赋值有关。由于语义差异,受访者对于不同等级的赋值与调查者不一致,如受访者“不满意”的语义理解平均为10分,而不是调查设计者给定的40分(见表3),此时按照式(1)的计算方法同样可以得到各市科技创新环境满意度平均得分。
表2 某省各市科技创新环境满意度排名方案及结果

变量十分不满意不满意一般满意十分满意有效样本平均得分(分)调查者等级设计值(分)0406080100--相邻等级分值差异(分)-40202020--A市(份)917525617115875163.7B市(份)479228418310270864.35…
表3 赋值改变后某省各市科技创新环境满意度

变量十分不满意不满意一般满意十分满意有效样本平均得分(分)受访者等级实际值(分)0106080100--相邻等级分值差异(分)-10502020--A市(份)917525617115875160.7B市(份)479228418310270860.45…
这个案例说明了调查者与受访者在等级语义上的差异,在统计评价中可能得到截然不同的测量结果和排名。李克特式量表在排名应用中可能由于语义差异带来错误的测量结果。因此,本文试图定量分析两个问题:①调查者赋值与受访者赋值差异多大时,采用传统调查者赋值的李克特式量表所得到的统计排序仍是正确的?②在受访者等级赋值状况不确定/不明情况时,如何得到相对准确的测量排序?
上述案例研究说明调查者与受访者的语义差异可能导致统计调查得到正确的排序结果。因此,在调查中什么程度的语义差异肯定不会导致错误的结果?为了研究这个问题,本文以科技创新环境满意度为例展开理论探讨,首先设定两个科技创新环境满意度评价的参评对象X和Y、受访者态度等级N等。用αi(i=1,...,N)表示受访者对第i个等级的赋值, PX(i)和PY(i)分别表示受访者对参评对象X和Y评价时选择第i等级的比例。参评对象X与Y的得分差异用ΔX,Y表示:
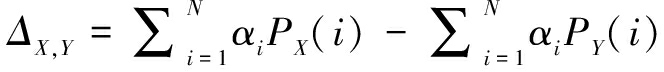
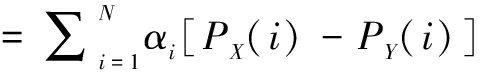
(2)
为了研究方便,设定参数βi符合如下条件:当i≥2时,βi=αi-αi-1;当i=1时,βi=αi。因此,可以用βi反映等级间赋值差距。根据βi的定义,可以得到如下等式:
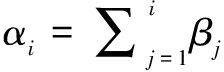
(3)
因此,将αi带入到公式(1)中,可以得到:
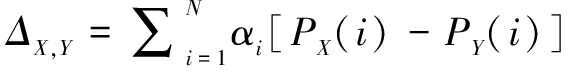
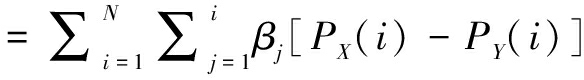
(4)
因此,设定X>Y表示受访者对X的评价高于对Y的评价,X~Y表示受访者给予X的评价等于其对Y的评价。因此,根据式(4),有如下定义:
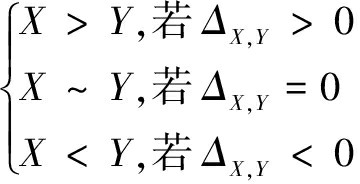
(5)
根据式(5),可以通过计算ΔX,Y的数值来比较受访者对X和Y的评价水平。调查员对第i等级的赋值是![]() 可以得到
可以得到![]() 当i≥2时
当i≥2时![]() ;当i=1时
;当i=1时![]() 采用τi表示调查者所用的
采用τi表示调查者所用的![]() 值偏离真实值βi的程度,即语义差异程度,可用如下公式表示τi:
值偏离真实值βi的程度,即语义差异程度,可用如下公式表示τi:
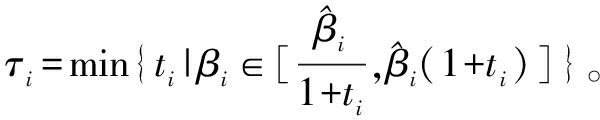
当τi=0(i=1,…,N)时,调查者使用的分值与评价水平完全对应,因此,调查结果是有效的;当τi→+∞(i=1,…,N)时,调查者使用的分值完全不能刻画受访者的评价程度,因此,调查结果和排序可能是无效的。设![]() 和
和![]() 可以得到如下命题:
可以得到如下命题:
命题1: 当τ≤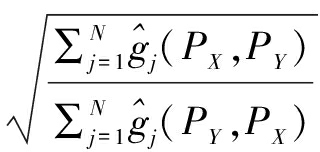 -1,(τ=max(τi|i∈[1,N]) )时,ΔX,Y与
-1,(τ=max(τi|i∈[1,N]) )时,ΔX,Y与![]() 同号。
同号。
证明:首先考虑受访者对X的评价高于Y的评价的情况,即ΔX,Y≥0有:
ΔX,Y≥0⟺![]()
⟺![]()
⟺![]()
⟺![]()
⟺![]() (gj(PX,PY)-gj(PY,PX))≥0
(gj(PX,PY)-gj(PY,PX))≥0
⟺![]()
因此,有:
ΔX,Y≥0⟺![]()
设定![]() 和
和![]() 求解如下两个不等式:
求解如下两个不等式:

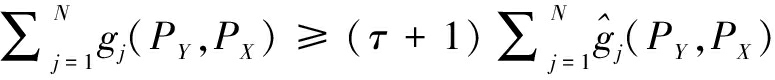
两个不等式可以化简为:
τ≤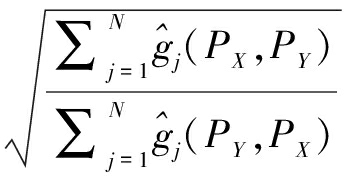 -1
-1
(6)
此时,可以发现,当式(6)满足时,有:
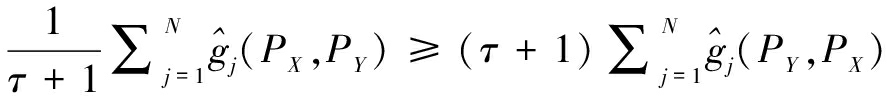
⟹![]()
⟹ΔX,Y≥0
因此,当语义差异τ≤-1时,调查者等级赋值得到的两个比较项X得分都会高于比较项Y,即排序与受访者等级赋值得到的结果相同。同样可以证明,当比较项X得分低于比较项Y,语义差异在以上范围内时,等级赋值语义差异不会影响两者的排序。
证毕。
命题1说明,当![]() 与βi的语义差异在一定范围内时,语义差异不会导致X和Y的排名判断错误。当然,在现实案例中可能有多于两个相互比较的对比方,如在本文第一部分案例中出现了超过两个进行评比的参评单位或地区。为了在多个比较项时描述方便,采用
与βi的语义差异在一定范围内时,语义差异不会导致X和Y的排名判断错误。当然,在现实案例中可能有多于两个相互比较的对比方,如在本文第一部分案例中出现了超过两个进行评比的参评单位或地区。为了在多个比较项时描述方便,采用![]() 表示-1,如果参与评比的对比方为M个,则根据命题1的结论可以得到:
表示-1,如果参与评比的对比方为M个,则根据命题1的结论可以得到:
推理1: 当![]() 时,参与评比的总排序不变。
时,参与评比的总排序不变。
证明:根据命题1可知语义差异在![]() 范围内时,第k个参评单位/地区和第l个单位/地区的排名不受到语义差异的影响。因此,当所有等级的语义差异不高于
范围内时,第k个参评单位/地区和第l个单位/地区的排名不受到语义差异的影响。因此,当所有等级的语义差异不高于![]() 的最低值时,所有参评的单位/地区的总排名不变。
的最低值时,所有参评的单位/地区的总排名不变。
证毕。
显然,定理1和推理1给出了两个评比方和多个评比方时能保证评比结果不变的语义差异最大值。两者说明语义差别在该范围内时,调查者的主观赋值即使与受访者赋值不一致,其排名测量结果也仍然保持正确。因此,在基于李克特式量表法进行的各种统计排名过程中,可以通过推理1得到的结论判断排名可靠性。
显然,得到受访者赋值后,即可通过上文得到的结论判别调查所得结果的正确性,与此同时,可以用受访者赋值代替调查者赋值,从而得到不存在语义差异的调查结论。然而,在很多情况下受访者赋值往往难以得到,如调查已经结束难以对企业受访者一一回访,或者调查规模较大而对企业受访者的赋值回访会耗费更多资源,此时,可以根据如下步骤得到相对稳健的赋值。根据推理1得到总体排名仍保持正确的语义差异最大值(称为最大可容忍语义差异),然后,根据小样本随机调查估计语义差异与最大可容忍语义差异的匹配程度,选择匹配度最好的赋值具有最高的可靠性。具体步骤如下:
步骤一:根据调查者设定![]() 得到差异值τ,并计算各自βi的最大可容忍范围
得到差异值τ,并计算各自βi的最大可容忍范围![]() 当所有受访者与调查者对每一等级的语义差异均在可容忍范围内时,根据推理1可知,调查者赋值得到的统计排名反映了真实的受访者排名。在实践中,不同受访者对同一等级的语义也可能不同。因此,采用如下步骤判断语义差异对统计结果的影响和应对方法。
当所有受访者与调查者对每一等级的语义差异均在可容忍范围内时,根据推理1可知,调查者赋值得到的统计排名反映了真实的受访者排名。在实践中,不同受访者对同一等级的语义也可能不同。因此,采用如下步骤判断语义差异对统计结果的影响和应对方法。
步骤二:对βi的取值展开小样本调查,确定调查样本包括在![]() 范围内的概率pri。其中,样本数量使用实验设计(DOE, design of experiment)来计算。实验设计给出了进行统计推断所需最小数据量,在一定显著性水平上保证试验结果的可靠性。从理论上,实验样本容量越大则所取得的实验结果可靠性越高。因此,在可行的情况下可以在实验样本容量基础上增加更多样本,从而进一步保证概率值计算的准确性。
范围内的概率pri。其中,样本数量使用实验设计(DOE, design of experiment)来计算。实验设计给出了进行统计推断所需最小数据量,在一定显著性水平上保证试验结果的可靠性。从理论上,实验样本容量越大则所取得的实验结果可靠性越高。因此,在可行的情况下可以在实验样本容量基础上增加更多样本,从而进一步保证概率值计算的准确性。
值得关注的是,受访者之间也存在语义差异,即对于同一等级,不同受访者的赋值βi可能不一样。由于调查者与受访者的语义差异在范围![]() 内时调查结果不受影响,语义差异在该范围内的受访者越多则调查结果受到的影响越小。理想情况下,针对所有受访者的语义差异都在这个可容忍范围内,此时语义差异不影响调查排名的统计结论。反之,超过语义差异可容范围的受访者越多,统计排名结论不可靠性就越大。
内时调查结果不受影响,语义差异在该范围内的受访者越多则调查结果受到的影响越小。理想情况下,针对所有受访者的语义差异都在这个可容忍范围内,此时语义差异不影响调查排名的统计结论。反之,超过语义差异可容范围的受访者越多,统计排名结论不可靠性就越大。
步骤三:计算![]() 由于对每一个等级都可能存在语义差异,将不同等级选项的概率值相乘从而得到涵盖所有等级的可靠性水平。由于所有pri∈[0,1],因此,R∈[0,1]。特别地,当所有等级的语义差异水平都在可容忍范围内即pri=1(i=1,…,N)时,则可靠性水平度量值达到最大值R=1,即当R值为1时,语义差异不会导致统计排序结果背离受访者的实际排序。
由于对每一个等级都可能存在语义差异,将不同等级选项的概率值相乘从而得到涵盖所有等级的可靠性水平。由于所有pri∈[0,1],因此,R∈[0,1]。特别地,当所有等级的语义差异水平都在可容忍范围内即pri=1(i=1,…,N)时,则可靠性水平度量值达到最大值R=1,即当R值为1时,语义差异不会导致统计排序结果背离受访者的实际排序。
根据以上3个步骤,可以得到调查者等级赋分的可靠性水平R。对于表3显示的调查结果,根据步骤二可以得到概率pri和有效样本数量,设两者分别为pr=[0.91,0.95,0.92,0.93]和NS=1 203(见表4)。
表4 某省各市企业科技创新环境满意度排名结果的可靠性分析

题项十分不满意不满意一般满意十分满意有效样本NS调查者等级赋值^αi0分40分60分80分100分-相邻等级赋值差异^βi-40分20分20分20分-概率pri-0.910.950.920.931203
根据步骤三,得到表3调查结论的可靠性水平:
R=![]() pri=0.91×0.95×0.92×0.93=0.739 6
pri=0.91×0.95×0.92×0.93=0.739 6
可以改变调查者等级赋值差距![]() 得到不同等级赋值方案下企业科技创新满意度调查结果和排名的可靠性水平。因此,通过反复改变调查者等级赋值方案,选择其中可靠性最高的等级赋值和调查排名。
得到不同等级赋值方案下企业科技创新满意度调查结果和排名的可靠性水平。因此,通过反复改变调查者等级赋值方案,选择其中可靠性最高的等级赋值和调查排名。
4.1 研究问题引发的相关讨论
以上研究重点分析了利用李克特式量表进行统计排名时语义差异带来的影响,以及如何降低语义差异带来的统计排名误差。同样,李克特式量表中的语义差异也可能在其它统计应用中导致错误的统计分析结论。例如,杜跃平和马晶晶[24]对陕西省高新技术开发区内部分科技创新企业展开了调查,分析科技创新企业对各项金融政策的关注度和满意度。该研究成功回收了233份有效调查问卷,受访企业对其中两项金融支持政策的满意度情况如表5所示。
表5 陕西省高新技术开发区内高新技术企业对金融支持政策满意度
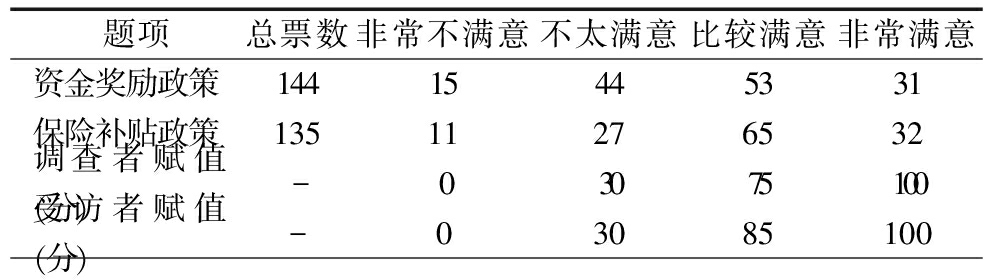
题项总票数非常不满意不太满意比较满意非常满意资金奖励政策14415445331保险补贴政策13511276532调查者赋值(分)-03075100受访者赋值(分)-03085100
表5中“资金奖励政策”和“保险补贴政策”分别指“首批新三板市场挂牌的企业可获50万元以内省专项资金奖励”和“高新区科技保险补贴资金1 000万元支持科技创新企业分散创业风险”。为了研究高新技术企业对这两项金融支持政策满意度水平是否一致,可以通过独立样本t检验比较受访者对两者满意度的均值。因此,当调查者对不同满意度等级的赋值分别为0、30、75和100分时,可以得到高新技术企业对两项金融支持政策均值的一致性检验结果(见表6)。
表6 基于调查者赋值的高新技术企业政策满意度均值一致性检验

独立样本检验莱文方差等同性检验F显著性平均值等同性t检验t自由度显著性(双尾)平均值差值标准误差差值差值95%置信区间下限上限调查者赋值假定等方差 9.5660.002-2.0242760.044-8.2174.060-16.210-0.224不假定等方差-2.029275.8350.043-8.2174.051-16.191-0.243
表6检验结果表明,高新技术企业对两项金融政策的满意度平均值在95%的置信水平下具有显著性差异,即两项政策的平均满意度水平不同。由于语义差异的干扰,受访者对不同满意度等级的赋值分别为0、30、85和100分时,同样可以得到高新技术企业对两项金融的平均满意度水平一致性检验(见表7)。结果发现,基于受访者赋值的高新技术企业对两项政策满意度水平的平均值在95%置信水平上接受原假设,即高新技术企业对两项金融支持政策的满意度水平没有显著性差异。表6和表7的结果表明,调查者与受访者在“比较满意”等级的语义差异会导致截然相反的调查结论。
表7 基于受访者赋值的高新技术企业政策满意度均值一致性检验

独立样本检验莱文方差等同性检验F显著性平均值等同性t检验t自由度显著性(双尾)平均值差值标准误差差值差值95%置信区间下限上限受访者赋值假定等方差6.9760.009-1.8602760.064-7.1093.823-14.6330.416不假定等方差-1.864275.8920.063-7.1093.814-14.6170.400
因此,在对李克特式量表得到的数据进行各类统计分析时,语义差异可能导致错误的分析结果。本研究主要以基于李克特式量表的调查统计排名为例,分析语义差异带来的影响,并从数理分析的角度证明李克特式量表对统计分析结果的影响程度以及减轻其负面影响的方法。后续研究可以针对不同统计方法,分析语义差异对各种统计分析结论的影响以及应对方法。
4.2 结论与未来研究方向
李克特式量表将受访者对某表述的认可程度转化为数值变量,并将之应用于各种统计方法中进而对所研究的问题展开统计分析。李克特式量表赋予不同量表选项一定的分值,但是,通常调查者根据经验对不同选项赋予分值,可能无法准确反映企业受访者的真实赋值,即语义差异可能导致调查分析结果的错误。因此,本文以李克特式量表分析地区科技创新环境排名为例,分析语义差异对统计排名的影响。首先给出了语义差异不会带来满意度调查排名错误的边界条件,在此基础上,提出了评价调查排名中语义差异带来的可靠性水平的基本步骤以及降低语义差异带来的排名错误的一般方法。
由于不同受访者对于同一等级的赋值可能不同,语义差异在可容忍外的部分离散程度也可能影响排名结果。因此,当对受访者可容忍概率相同的两组调查者赋值方案作比较时,受访者赋值的峰度和偏度是影响赋值方案可靠性的条件,是未来重要研究话题。与此同时,本文给出了调查者不同等级赋值方案的可靠性水平,并从中选择可靠性水平最高方案作为最优赋值方案,未来可以探讨满足具体实际应用需求的可靠性水平范围。更进一步,本文研究李克特量表中语义差异对统计排名的影响,发现语义差异对其它统计分析也有显著影响,未来可深入研究语义差异对其它统计分析的影响。
参考文献:
[1] HUIJBREGTS H J, KHAN R J K, FICK D P, et al.Prosthetic alignment after total knee replacement is not associated with dissatisfaction or change in Oxford Knee Score: a multivariable regression analysis[J].The Knee, 2016, 23(3): 535-539.
[2] 王元地,陈禹.区域“双创”能力评价指标体系研究——基于因子分析和聚类分析[J].科技进步与对策, 2016, 33(20): 115-121.
[3] 徐顽强,孙正翠,周丽娟.基于主成分分析法的科技服务业集聚化发展影响因子研究[J].科技进步与对策, 2016, 33(1): 59-63.
[4] 潘雁,叶颖,朱珺,等.应用 SF-36 量表分析高血压患者生命质量 (QOL) 的影响因素[J].复旦学报 :医学版, 2014, 41(2): 205-209.
[5] SULLIVAN G M, ARTINO JR A R.Analyzing and interpreting data from Likert-type scales[J].Journal of Graduate Medical Education, 2013, 5(4): 541-542.
[6] 王爽, 刘彦兵, 刘轶芳.海淀区科技创新型企业发展能力评价研究[J].数学的实践与认识, 2013, 43(19): 76-83.
[7] 俞立平,潘云涛,武夷山.科技评价中同行评议与指标体系关系的研究——以《泰晤士报》世界大学排名为例[J].科学学研究, 2008, 26(5): 927-931.
[8] 董彦斌,孙慧,张其.基于主成分分析的区域科技创新能力评价[J].科技进步与对策, 2012, 29(12): 26-30.
[9] 陈文军, 梅姝娥.江苏省主要城市科技竞争力比较研究[J].科技管理研究, 2014, 34(13): 47-51.
[10] 曹梦.山西省 11 地市科技创新能力与创新效率研究[D].太原:中北大学, 2015.
[11] 段小薇, 李璐璐, 苗长虹, 等.中部六大城市群产业转移综合承接能力评价研究[J].地理科学, 2016, 36(5): 681-690.
[12] LIKERT R.A technique for the measurement of attitudes[J].Archives of Psychology, 1932(4).
[13] ERTO P, VANACORE A.A probabilistic approach to measure hotel service quality[J].Total Quality Management, 2002, 13(2): 165-174.
[14] GROBELNA A, MARCISZEWSKA B.Measurement of service quality in the hotel sector: the case of Northern Poland[J].Journal of Hospitality Marketing & Management, 2013, 22(3): 313-332.
[15] AWAN M U, MAHMOOD K.Development of a service quality model for academic libraries[J].Quality & Quantity, 2013, 47(2): 1093-1103.
[16] YURTSEVEN H R.Service quality of troy: an importance-satisfaction analysis[D].Germany: University of Muenchen,2005.
[17] 乔柱, 杨国盛, 章文俊.双极主观等级量表的级别选取[J].机械设计与研究, 2009, 25(4): 70-72.
[18] LEHMANN D R, HULBERT J.Are three-point scales always good enough [J].Journal of Marketing Research, 1972, 9(4):444-446.
[19] 李亚红.大学新生SCL-90量表计分与赋值计分的差别研究[J].保健医学研究与实践, 2010(4): 33-34.
[20] OLSSON U, DRASGOW F, DORANS N J.The polyserial correlation coefficient[J].Psychometrika, 1982, 47(3): 337-347.
[21] 亓莱滨.李克特量表的统计学分析与模糊综合评判[J].山东科学, 2006, 19(2): 18-23.
[22] 简明,魏泉红.顺序量表的矛盾[J].统计与决策, 1998 (6): 42-42.
[23] TAN C,HAN G,GOH T.Service quality comparison[C].Asian Network for Quality Congress, 2014.
[24] 杜跃平, 马晶晶.科技创新创业金融政策满意度研究[J].科技进步与对策,2016,33(9):9.
(责任编辑:万贤贤)
The Effect of Semantic Difference of Likert-type Questionaires on Scientific Measurements
Abstract:Likert-type questionaires quantify the interviewees' opinions and are often employed in many applications, including regional ranking of technological innovation environment. Some options are provided in the items of Likert-type of questionaires and the interviewees are asked to select one option from the displayed ones. Each option indicates different scales, based on which the total scores of all interviewees are calculated. However, the interview is mandaterly to select one choice from the displayed options and the scale of the selected option is provided by the invesgator, where the provided scale might not equal to the interviewee's opinion. The difference is named by semantic difference. Since the semantic bias on scores that provided by the interviewee and invesgator, the scientific measurements based on the data collected by Likert-type questionaires may leads to unrobust conclusions. After giving a normal defination of semantic difference, the paper suggest an application of Likert-type questionaires in regional ranking of technological innovation to illustrate the affections of the semantic differnece. Moreover, the mathematical and numberical analyses are employed to analyze how much semantic difference is torerated for a robust result of ranking and some suggestions to reduce semantic difference are also given in the end of the study. An numerical study is provided to present the theorical findings of the study and show the calculating process that suggested in the paper.
Key Words:Likert-type of Questionnaire; Semantic Difference; Scientific Measurement
中图分类号:G304
文献标识码:A
文章编号:1001-7348(2017)20-0001-06
收稿日期:2017-05-11
基金项目:国家自然科学基金项目(71501128,71371122,71632008);国家哲学社会科学基金重大研究项目(14ZDB152);上海交通大学文理交叉基金项目(15JCZY05)
DOI:10.6049/kjjbydc.2017020128