摘 要:高技术产品是高新技术知识的集成,其研发状况成为知识经济增长的决定性因素之一。围绕组织学习-知识存量-研发绩效的作用链条,构建了高技术产品研发过程中学习双元平衡的最优控制模型,求解出探索式学习和利用式学习的最优终止点、最优转换点、最优投入强度,并从这3个方面给出了高技术产品研发过程中的学习双元最优顺序策略。研究结论可为高技术产品研发项目实施中研发节奏掌控、学习战略的制定、资源分配等方面提供参考。
关键词:研发项目;知识存量;组织学习;最优控制
知识经济时代,知识资源是创新发展的源泉,如何持续、高效地获取技术知识成为组织竞争优势提升的关键。高技术产品具有知识高度密集的特点,是高新技术知识的集成,其研发过程充分体现了对高新技术知识的创造及获取。如何提升高技术产品研发绩效、实现知识积累成为各界关注的热点。Nonaka[1]的知识创造理论指出,组织知识来源于学习行为;Pisano[2]的竞争能力理论也指出知识基础形成的关键前因是组织学习。因此,组织学习会对高技术产品研发中的知识积累及研发绩效产生决定性影响。本文围绕高技术产品研发中的知识积累最大化目标,探究此过程中的组织学习最优化配置。
March[3]指出,组织学习可分为探索性学习与利用性学习,两者作为知识创造方式,缺一不可。但是,两种学习方式间又有着固有张力:前者实质是新知识的创造,后者是对现有知识的整合应用。组织需要协调二者关系,尤其对研发项目而言,较强的资源约束性及成员交互性使得平衡两种学习方式尤为困难。当前,项目层面的双元学习研究不多,使用数学方法的定量分析更少。例如,Drach[4]、Reilly[5]、林枫[6]等指出,项目层面的探索活动与利用活动会相互渗透,但又各有侧重,在项目期内呈现出两类活动间断出现、顺序平衡,其核心问题是如何摆脱持续探索(或利用)形成的失败陷阱和路径依赖[7],但研究迄今尚未对此问题形成一致结论。Rothaermel等[8]研究生物技术行业产品研发过程,指出最优学习策略是先探索后利用;廖勇海等(2015)指出,国内上市企业的最优学习方式为在持续利用中适时探索,即先利用后探索。哪种策略更适合高技术产品研发?如何确定探索与利用间的最优转换时机?如何避免过度学习的发生?围绕这些问题,本文详细阐释探索式学习与利用式学习在高技术产品研发项目中的平衡实现过程,以项目绩效最大化为目标,构建学习双元的动态控制模型,从组织学习终止点、探索与利用转换点、学习投入强度3个方面给出高技术产品研发项目双元学习的最优顺序策略。
组织学习的结果是形成知识存量,在高技术产品研发项目中体现为研发人员研发知识和经验积累、开发产品中技术凝聚等,即在某时间点上累积的知识总量。为体现探索式学习与利用式学习对知识存量作用的差异,本文将研发项目知识存量解构为知识水平和知识离散度两个维度,前者表征项目在关键领域的知识储量及其对该领域复杂问题的解决程度,后者则反映了项目拥有的知识元素与知识水平间的差距[9]。探索行为为项目带来全新知识,增加了知识离散度,而新知识消化吸收后拓展了原有知识基础[10]、提升了知识水平。利用行为则是对某领域知识的深入挖掘,有利于知识水平提升,但不能增加新的知识元素,并且持续性利用行为会形成组织惯性[11],局限项目学习的关注点,使其丧失对某些边缘知识点的掌控,即利用行为的持续开展会降低知识离散度。组织学习行为强调学习过程及对新知识的识别、获取,但探索式学习面临的问题是全新的,项目团队既没有问题的确切答案,也没有可以演绎的知识基础[12];利用式学习是对现有问题的深层探究,是在现有知识基础上开展的进一步挖掘。因此,与探索式学习相比,利用式学习与当前知识存量的关系更为密切,而当前知识存量可视为利用式学习开展的投入元素之一。
本文研究中的研发项目绩效主要是指高技术产品研发活动带来的收益增加。知识存量作为研发项目的重要资产,与绩效间存在正相关关系[13],知识存量越大越有利于技术商业化,带来更多收益回报。Gaimon等[14]认为,研发产品产生的收益与研发项目终止时的知识存量间存在函数关系。但是,知识水平和知识离散度对绩效的作用存在差异,较高的知识水平意味着项目在关键技术领域积累了大量经验,而这会增强决策者对有价值技术的辨识能力[15],从而减少项目技术失误。另外,知识水平提升有助于解决原有技术问题,使得相关成本不断下降。因此,知识水平能促进绩效提升。知识离散度的加大可使决策者接触到更多新知识,从而增加项目获利机会[16]。但是,新知识的引入需要耗费成本,过于多样的知识组合也需要支付更多协调费用,而研发项目有着资源约束性,过大的知识离散度会使知识结构杂乱无序,进而降低项目绩效[15]。因此,项目研发应保持适度的知识离散度[17],因其与研发项目绩效间存在倒U型关系。
基于以上讨论,考虑到模型的简洁性及适用性,本文对研究思路作出如下设定:
(1)高技术产品研发项目中,探索式学习会提升知识水平,也会增大知识离散度;利用式学习会提高知识水平,但会减小知识离散度。
(2)利用式学习需要以当前知识为基础,当前知识水平越高,其对知识水平提升的作用越强;当前知识离散度越大,其对知识离散度降低的作用越强。
(3)高技术产品研发项目绩效与知识水平间呈单调递增关系,与知识离散度间呈倒U型关系。
上述设定在众多实证研究中均已得到证实,是本研究模型分析的理论基础。
2.1 约束函数
界定T为高技术产品研发项目的持续期,t([0, T]是项目过程中的某具体时点;控制变量是组织学习的两种方式:t时刻对探索式学习的资源投入率为r(t),即该时刻单位时间内投入到探索性学习活动中的工时或资金的增量,t时刻对利用式学习的资源投入率为i(t),即该时刻单位时间内投入到利用性学习活动中的工时或资金的增量;r(t)≥0,i(t)≥0;状态变量是知识存量,其中t时刻研发项目知识水平度为n(t),知识离散度为p(t),n(t)>0,p(t)>0。与利用式学习相比,探索式学习对知识存量的影响有着滞后性[3],本文引入滞后分布函数μ(t-φ)[18],满足条件0≤μ(t-φ)≤1,且![]() μ(t-φ)dφ=1,此函数发生在探索的知识实现过程中。
μ(t-φ)dφ=1,此函数发生在探索的知识实现过程中。
高技术产品研发过程中外部环境有着较大动态性:技术进步、市场环境、顾客偏好等因素的变动较为稳定时,未来预测精确度较高,会更倾向于对现有知识、技术的整合运用;当环境因素变动剧烈时,突发状况使得利用式学习价值降低,为快速把握机会需要与外部进行交互并及时引入新知识,探索的使用频率会更大[19]。故本文引入环境动态系数ρ∈[0,1],ρ越大说明项目外部环境愈为动荡、难以预测,此时利用对知识存量的作用程度会越小,而探索的作用程度会愈强。
综合以上分析,探索式学习、利用式学习对知识存量的动态作用过程如下:
![]() =ρ
=ρ![]() α1μ(t-φ)r(φ)dφ+(1-ρ)β1i(t)n(t)
α1μ(t-φ)r(φ)dφ+(1-ρ)β1i(t)n(t)![]() (1)
(1)
![]() =ρ
=ρ![]() α2μ(t-φ)r(φ)dφ-(1-ρ)β2i(t)p(t)
α2μ(t-φ)r(φ)dφ-(1-ρ)β2i(t)p(t)![]() (2)
(2)
式(1)表示探索式学习对知识水平(离散度)的作用,式(2)表示利用式学习对知识水平(离散度)的作用。其中,α1(α2)表示探索式学习对知识水平(离散度)的边际作用,β1(β2)表示利用式学习对知识水平(离散度)的边际作用,α1(α2)>0、β1(β2)>0,α、β的 值与研发团队初始知识配置及成员间交互频率有关。
2.2 目标函数
根据前文所述,界定([n(T),p(T)]为高技术产品研发项目绩效函数,∂π/∂n>0。将研发活动成本分为两类,即学习成本与其它成本。前者包括成员薪金、劳务费、培训费、实验成本等,会随学习强度变化而变化,因而将其细分为探索性学习成本与利用性学习成本。定义参数c1(c2)为探索式学习(利用式学习)的边际成本,重复投资会使研发实验、人才培训等成本发生变化,故使用二次成本函数形式;其它成本是除组织学习相关的成本外的其它开支,每期额度较为固定,将其界定为C0,主要涉及研发中的设施折旧、场地开支等。
综上,探索式学习与利用式学习对研发项目绩效影响的目标函数可表示为:
Maximizeπ[n(T),p(T)]-![]() [C0+1/2c1r2(t)+1/2c2i2(t)]dt
[C0+1/2c1r2(t)+1/2c2i2(t)]dt![]() (3)
(3)
式(1)、(2)、(3)共同构成了高技术产品研发项目学习的最优双元控制模型。
3.1 模型求解
引入共态变量λ1(t)、λ2(t)分别表示因n(t)、p(t)提升而在目标函数上产生的边际收益。为了便于分析,引入x1(t)、x2(t)表示t时刻投入n(t)、p(t)引起的项目期内绩效变动的累计:
x1(t)=![]() μ(φ-t)λ1(φ)dφ,x2(t)=
μ(φ-t)λ1(φ)dφ,x2(t)=![]() μ(φ-t)λ2(φ)dφ
μ(φ-t)λ2(φ)dφ![]() (4)
(4)
式(4)计算后可得:
dxi(t)/dt=-μ(T-t)λi(T)+![]()
![]() μ(φ-t)dφ,i=1,2
μ(φ-t)dφ,i=1,2![]() (5)
(5)
H=-C0-1/2c1r2(t)-1/2c2i2(t)+λ1(t)ρ![]() α1μ(t-φ)r(φ)dφ+(1-ρ)β1λ1(t)i(t)n(t)
α1μ(t-φ)r(φ)dφ+(1-ρ)β1λ1(t)i(t)n(t)
+λ2(t)ρ![]() α2μ(t-φ)r(φ)dφ-(1-ρ)β2λ2(t)i(t)p(t)
α2μ(t-φ)r(φ)dφ-(1-ρ)β2λ2(t)i(t)p(t)![]() (6)
(6)
由此,建立Hamiltonian函数。H函数反映了短期约束下的项目绩效前景,表示当前收益与未来效益的综合性绩效。对式(4)、(5)、(6)进行积分转换得到:
H=-C0-1/2c1r2(t)-1/2c2i2(t)+ρα1r(t)x1(t)+(1-ρ)β1λ1(t)i(t)n(t)+ρα2r(t)x2(t)-(1-ρ)β2λ2(t)i(t)p(t)![]() (7)
(7)
函数H存在最优解的条件是:
dλ1(t)/dt=-∂H/∂n(t)=-(1-ρ)β1λ1(t)i(t)<0,λ1(T)=∂π/∂n(T)![]() (8)
(8)
dλ2(t)/dt=-∂H/∂p(t)=(1-ρ)β2i(t)λ2(t),λ1(T)=∂π/∂p(T)![]() (9)
(9)
此时,H函数的最优轨线为:
∂H/∂r=-c1r(t)+ρα1x1(t)+ρα2x2(t)=0![]() (10)
(10)
∂H/∂i=-c2i(t)+(1-ρ)β1λ1(t)n(t)-(1-ρ)β2λ2(t)p(t)=0![]() (11)
(11)
求解后,得到:
r0(t)=ρ[α1x1(t)+α2x2(t)]/c1,i0(t)=(1-ρ)[β1λ1(t)n(t)-β2λ2(t)p(t)]/c2![]() (12)
(12)
3.2 学习双元动态模型最优解分析
3.2.1 组织学习持续临界点
由式(12)可得,t时刻研发项目组织学习的最优投入为:

知识水平对绩效发挥正向作用,故λ1(t)>0、x1(t)>0。知识离散度对绩效的作用不明确,故λ2(t)、x2(t)的正负未知。当r*(t)、i*(t)值为零时,应停止对探索式学习或利用式学习的投入。由此,可得到如下结论:如果存在时间点ts∈(0, T),使得β1λ1(ts)n(ts)=β2λ2(ts)p(ts),则ts是利用式学习的最优终止点;如果存在时间点tq∈(0, T),使得α2x2(tq)=-α1x1(tq),则tp是探索式学习的最优终止点。
March[3]指出,过度学习会让组织陷入两类陷阱。那么,如何确定学习的度呢?根据前文所述,高技术产品研发项目中知识离散度与绩效间存在倒U型关系(如图1所示),而持续利用学习会降低知识离散度[11]。因此,如果持续开展利用式学习,必然会使p(t)进入[0,p*]区域,导致绩效下降;当p(t)降低到p1时,综合绩效H为零,此后仍开展利用式学习会使绩效变为负值,故为保证综合绩效的获取,应在p1终止对利用式学习投入。求解分析得到p1对应的时间点需满足ts,即持续利用式学习通过降低知识离散度对绩效产生边际收益递减效应,通过强化知识水平产生边际收益递增效应,当二者相等时,应停止利用式学习,否则递减收益超出递增收益会降低绩效。持续探索式学习会加大知识离散度,如果持续开展探索式学习,必然会使p(t)进入[p*,∞]区域,导致项目绩效不断下降;当p(t)增到某点p2时,综合绩效H为零,此后H变为负值,则p2是探索式学习的最优终止点。求解分析得到p2对应的时间点需满足tq,即持续探索式学习通过增大知识离散度对绩效产生边际收益递减作用,通过强化知识水平产生边际收益递增作用,当二者作用相等时,应停止探索。探索式学习效果具有滞后性,因而使用累积边际收益的形式。
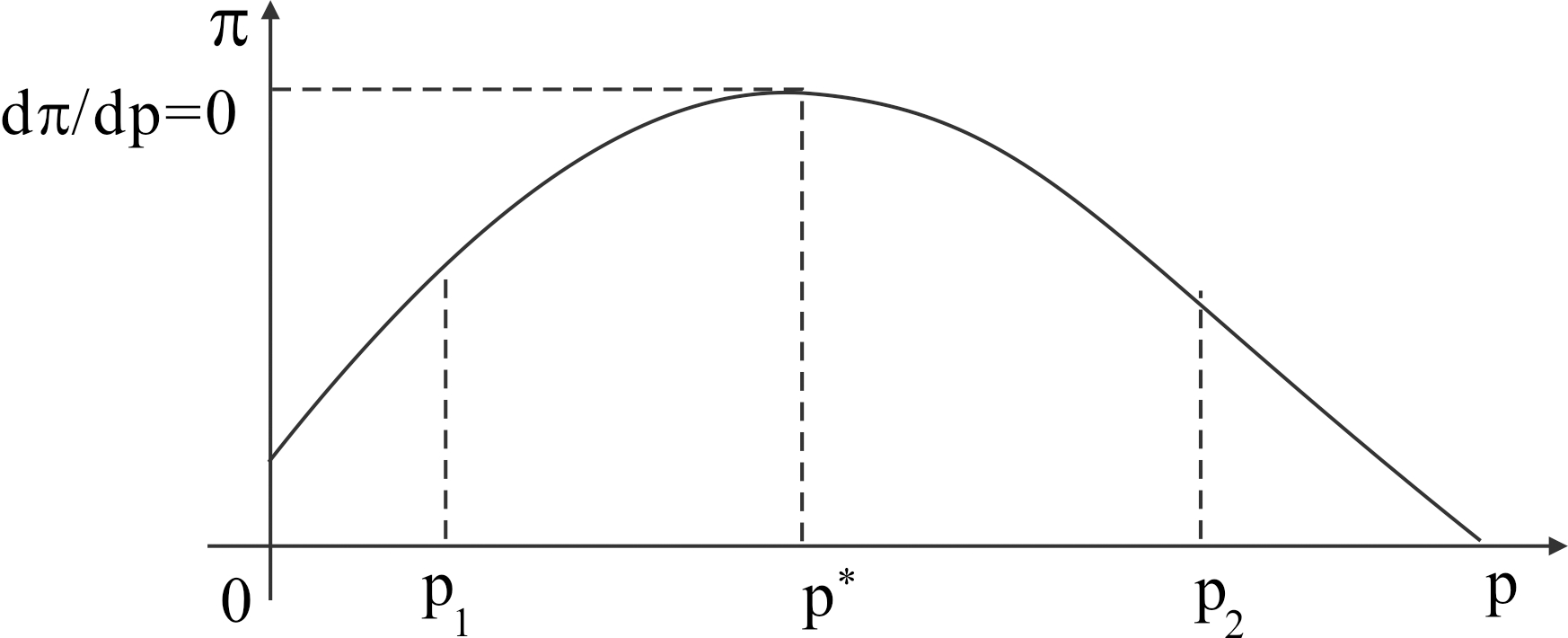
图1 高技术产品研发项目知识离散度对综合绩效的作用
3.2.2 组织学习顺序转换策略分析
由式(12)可知,对探索或利用的动态最优投入取决于环境动态强度(ρ)、边际成本(ci)、相关边际贡献(α1、β1),据此将研发项目动态双元平衡分为3种情形:
情形1:存在点tm∈(0,T),满足r*(tm)=i*(tm)。当t∈[0,tm)时,r*(t)>i*(t);当t∈(tm,T)时,r*(t)<i*(t)。
情形2:存在点tn∈(0,T),满足r*(tn)=i*(tn)。当t∈[0,tn)时,r*(t)<i*(t);当t∈(tn,T)时,r*(t)>i*(t)。
情形3:任意t∈(0,T),均有r*(t)>i*(t)或r*(t)<i*(t);
由式(12)可知,r*(t)、i*(t)值大小受参数ρ、c1(c2)影响。当ρ较大时,动荡的技术或市场环境中蕴含着诸多机会,此时如果探索式学习拥有收益(α1)及成本(c1)的相对优势,则项目会对其进行大量投入以捕捉机会,此时探索式学习的边际收益远大于利用式学习。随着时间推移,项目对环境逐步熟悉,环境中可探索的机会逐渐减少,从而探索式学习产生的边际收益逐渐降低,而此过程中探索式学习产生的新知识使得利用式学习的边际收益逐期提高。探索式学习与利用式学习自产生的边际收益在tm点相等,此后利用式学习的边际收益将超过探索式学习,最优投入决策则应将重心转换向利用活动。当ρ较小时,环境相对稳定 、可捕捉的机会较少,此时如果利用活动具有收益(β1)及成本(c2)的相对优势,则项目会倾向开展利用式学习。随着时间推移,逐期利用积累了较多的知识,使得组织对环境机会的识别及把握能力越来越强,促使其探索行为实施频率不断提高,到达tn点时,二者相等;当ρ极端大(或极端小)时,c1、c2及α1、β1的差异显著,研发项目过程中探索或利用活动的边际收益均有优势,此时项目对当前学习方式具有持续投入优势,不存在学习方式的转换。
综上可知,当转换点te满足情形1时,高技术产品研发项目学习双元最优策略为探索-利用策略;当转换点te满足情形2时,研发项目学习双元最优策略为利用-探索策略;当情形3出现时,研发项目应采取单一组织学习策略。
3.2.3 组织学习投入强度策略分析
由式(12)可得,探索式学习与利用式学习最优投入的瞬时变动率为:
dr*(t)/dt=ρ{[α1x1(t)/c1]'+[α2x2(t)/c1]'}![]() (14)
(14)
di*(t)/dt=(1-ρ){[β1λ1(t)n(t)/c2]'-[β2λ2(t)p(t)/c2]'}![]() (15)
(15)
根据学习过程中最大投入发生时点的不同,投入强度策略有前载策略与后载策略2种方式:前者是学习起始即投入最高学习强度,而后递减,以充分发挥投入资源的价值;后者是对学习投入逐期递增,期末时的投入强度达到最高,这能较好地激发学习过程中累积的知识的作用。研发项目每种学习方式的最优投入强度策略可以通过对dr*/dt、di*/dt的分析得到。
将式(1)、(2)、(8)、(9)带入式(14)、(15)后可得:
dr*(t)/dt=ρ[α1dx1(t)/dt+α2dx2(t)/dt]/c1![]() (16)
(16)
di*(t)/dt=(1-ρ)i(t)[β1α1x1(t)-β2α2x2(t)]/c2![]() (17)
(17)
式(5)表明,x1(t)>0,dx1(t)/dt<0,此时dr*/dt、di*/dt的正负取决于dx2/dt、x2(t)。
情形1:当x2(t)<0,或者x2(t)>0但β1远大于β2时,di*/dt>0,则对利用式学习的投入采取后载策略;
情形2:当x2(t)>0,且β1远小于β2时,di*/dt<0,则对利用式学习的投入采取前载策略;
情形3:当dx2(t)/dt<0,或者dx2(t)/dt>0但α1远大于α2时,dr*/dt<0,则对探索式学习的投入强度采取前载策略;
情形4:当dx2(t)/dt>0,且α1远小于α2时,dr*/dt>0,则对探索式学习的投入强度采取后载策略;
由式(4)可知,x2(t)的正负取决于λ2(t),而λ2(t)反映了知识离散度p(t)的变化情况。当λ2(t)>0时,p(t)呈增长趋势,初始离散度p(0)相对较小,此时x2(t)>0;λ2(t)<0时,p(t)呈减小趋势,初始离散度p(0)相对较大,此时x2(t)<0。
由式(5)可知,dx2/dt的正负取决于λ2(T)与dλ2(t)/dt在[t, T]间的累积。如图1所示,当p(0)>p*时,λ2(t)<0,由式(9)得dλ2(t)/dt<0,离散度p(t)在减小;当p(t)减至p*左侧时,λ2(t)>0,dλ2(t)/dt>0;当p(t)与p*相距较近时,p*左侧的dλ2(t)/dt累积不及其在p*右侧的累积,此时λ2(T)>0,dλ2(t)/dt<0,即dx2/dt<0。反之,当p(0)<p*时,λ2(t)>0,dλ2(t)/dt>0;p(t)增大至p*右侧,dλ2(t)/dt<0,当dλ2(t)/dt右侧的累计值未超过左边的累计值时,整体累积为正,此时λ2(T)<0,dλ2(t)/dt>0,即dx2/dt>0。
由以上分析可得到以下结论:当p(0)较大且α2>β2时,探索式学习采取前载投入策略;当p(0)较小且α2<β2时,若α1远大于α2则探索式学习采取前载投入策略,若α1远小于α2则探索式学习采取后载投入策略;当p(0)较大时,利用式学习采取后载投入策略;当p(0)较小,若α1β1远大于α2β2则利用式学习采取后载投入策略,若α1β1远小于α2β2则利用式学习采取前载投入策略。
3.3 高技术产品研发项目学习双元最优顺序策略
基于以上分析,总结高技术产品研发项目学习双元的顺序策略如表1所示。
表1 高技术产品研发项目学习双元顺序策略
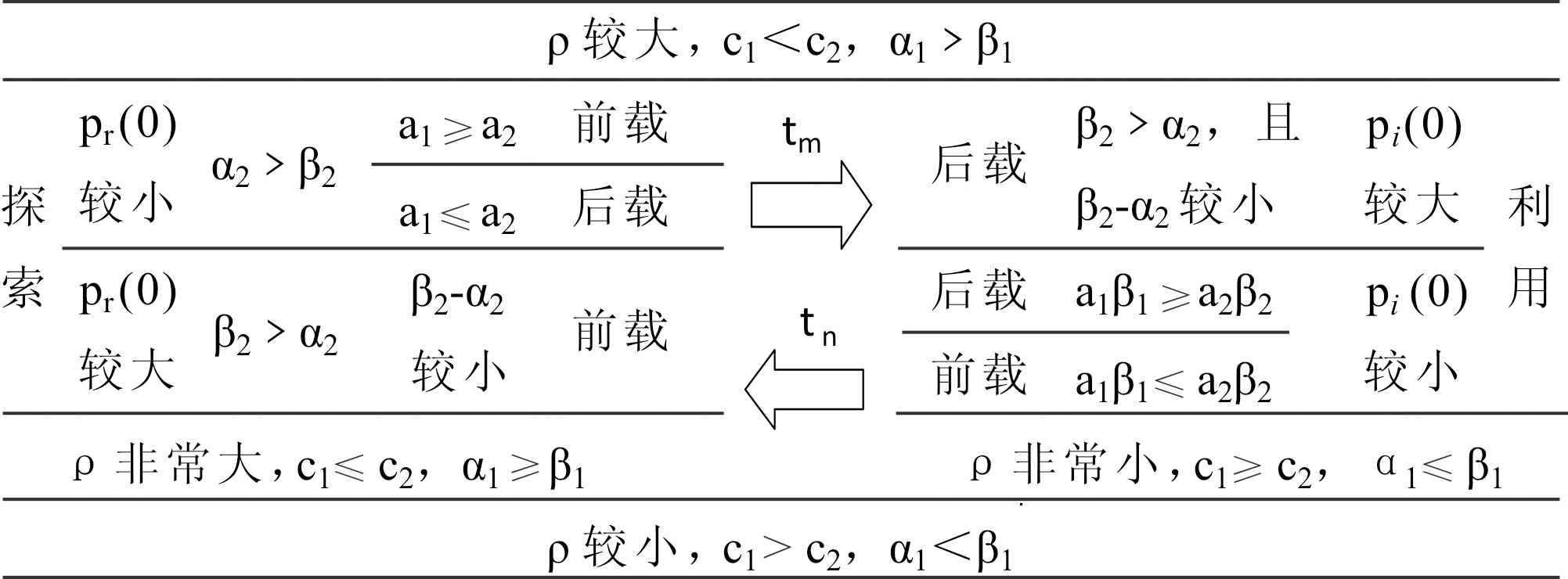
注:pr(0)表示探索式学习开展的初始知识离散度,可以根据团队成员的知识分布、学历状况、技术经验等进行预判;pi(0)的预判同上
高技术产品研发项目组织学习开展过程中,有4种可供选择的双元顺序策略:
(1)探索-利用策略。该策略适用于ρ较大,c1<c2,α1>β1的状况。前期对探索式学习投入较大,当达到时间点tm后,主要投入转向利用式学习,学习投入强度根据表1参数确定。此种策略适用于研发环境较为动荡、初始知识储备较少的项目团队,探索式学习对知识积累的边际贡献更大,项目资源应首先投入对新知识的探求;随时间推移,当利用对知识积累的边际收益超过探索时,将资源投入重点转移至对现有知识的消化与开发上。项目研发期间,探索与利用的投入强度会不断调整以最大化资源使用效率。
(2)利用-探索策略。该策略适用于ρ较小,c1>c2,α1<β1的状况,前期对利用式学习投入更多,当达到时间点tn后,主要投入转换为探索式学习,学习投入强度根据表1参数确定。此种策略适用于研发环境相对稳定、初始知识储备较多的项目团队。此时,对项目现有知识的消化、整合能为项目带来更大的知识贡献,即首先应重点开展利用;随着时间的推移,内部知识吸收殆尽,资源投入重点随之转移到对新知识的开发上。项目期间,探索与利用的投入强度会不断调整以最大化资源使用效率。
(3)探索主导策略。该策略适用于ρ非常大,c1远小于c2,α1远大于β1的状况,T时间内探索式学习占据投入主导地位,对利用式学习只有较少投入甚至不投入,投入强度策略根据表1中参数确定。此种策略适用于研发环境极为动荡、项目团队初始知识储备极少、项目持续周期较短的情境。此时,项目内部没有知识可挖掘,知识积累只能通过引入新知识实现,且项目持续期未达到两种学习方式转化的临界点便结束,即整个项目期内会持续对新知识进行探索,逐渐形成项目知识积累。探索式学习投入强度在此期间需不断调整。
(4)利用主导策略。该策略适用于ρ非常小,c1远大于c2,α1远小于β1的状况,T时间内利用式学习占据资源投入主导地位,对探索式学习投入较少甚至不投入,投入强度策略则根据表1中参数决定。此种策略适用于研发环境稳定、初始知识储备极大、项目持续周期较短的项目团队。此时,项目内部潜在知识丰富,稍加挖掘便能形成知识积累,而探求新知识则需付出更多成本,因而项目资源会优先投放至利用式学习。项目持续期未达到两种学习方式转化的临界点,即项目结束前会持续对利用式学习进行资源投入,投入强度会随相关参数变化而不断调整。
以上4种策略中,每种学习方式如果满足时间点ts或tp,则应停止对该学习方式投入,而将全部资源集中于其它学习方式的开展,直至越过ts或tp点后,再根据表1中的参数作出决策。项目运作过程中,可根据学习行为对知识积累的边际及累计贡献确定合理的学习截止点,以避免过度学习、规避风险。
高技术产品是企业高新技术知识的载体,产品研发过程即是知识创造、积累过程。该过程需要以组织学习为基础,而知识存量会对研发项目绩效产生影响。本文围绕知识存量变化与研发项目绩效关系,构建了探索式学习与利用式学习的投入最优决策模型,分析归纳了面向研发项目绩效提升的组织学习顺序策略,主要有以下结论:
(1)高技术产品研发项目应根据外部环境、内部初始知识状态等参数合理制定学习顺序策略,以最大化项目绩效。备选学习顺序策略有4种:探索-利用式策略、利用-探索式策略、探索主导型策略、利用主导型策略。
(2)高技术产品研发过程中,单一学习方式不能过度开展:当利用式学习通过影响知识深度和知识广度而对绩效产生的边界收益相等时,此时间点为利用式学习的最优截止点;当探索式学习通过影响知识深度和知识广度而对绩效产生的收益累积和为零时,此时间点为探索的最优截止点。
(3)当研发项目对探索式学习和利用式学习的最优投入相等时,该时刻是两类学习方式动态平衡的最佳转换时机。根据该转换时机所处情境,项目可分别采取探索-利用学习策略或利用-探索学习策略以最大化项目绩效。
上述结论对高技术产品研发项目的高效运作有着重要启示:首先,高技术产品研发既需要探求全新的技术知识,也需要对现有知识进行充分消化,但两种活动不能过度开展。项目可通过对知识积累的边际贡献确定恰当的实施度,从而科学地规避风险;其次,高技术产品研发过程中,需对新技术研发及现有知识消化适时转换,根据相关项目成本和项目知识基础确定二者转化的时机,以更好对项目研发节奏进行掌控;再者,高技术产品研发受到资金、人员、时间等因素影响,应根据不同研发行为对知识积累的边际贡献及产生的知识累积等因素相宜地配置资源,使项目资源得到更高效地利用。从知识积累及组织学习视角看,高技术产品研发项目需对团队知识分布、研发行为产生的知识边际效益、外部环境动荡水平等因素全面把握,在此基础上选取合理的学习顺序策略,以实现项目短期效益提升与长期优势获取的综合目标。
本文运用数学工具对高技术产品研发项目的学习行为优化展开研究,验证性的实证或案例分析尚需更深入的开展。此外,本文模型中关于组织学习与知识积累间关系的理论设定存在一定局限性,对于不符合模型设定的极端情境有待进一步探讨。
参考文献:
[1] NONAKA I. A dynamic theory of organizational knowledge creation[J]. Organization Science, 1994, 5(1): 14-37.
[2] PISANO G P. Knowledge, integration, and the locus of learning: an empirical analysis of process development[J]. Strategic Management Journal, 1995, 15(s1): 85-100.
[3] MARCH J G. Exploration and exploitation in organizational learning[J]. Organization Science, 1991, 2(1): 71-87.
[4] DRACH-ZAHAVY A, SOMECH A, GRANOT M.Can we win them all? benefits and costs of structured and flexible innovation-implementations[J]. Journal of Organizational Behavior, 2004, 25(2): 217-234.
[5] O'REILLY C, TUSHMAN M. Organizational ambidexterity: past, present and future[J]. Social Science Electronic Publishing, 2013, 27(4): 324-338.
[6] 林枫,孙小微,张雄林,等.探索性学习-利用性学习平衡研究进展及管理意义[J].科学学与科学技术管理,2015,36(4):55-63.
[7] GUPTA AK, SMITH KG, SHALLEY CE. The interplay between exploration and exploitation[J]. Academy of Management Journal, 2006, 49(4):693-706.
[8] ROTHAERMEL F T, DEEDS D L. Exploration and exploitation alliances in biotechnology: a system of new product development[J]. Strategic Management Journal, 2004, 25(3): 201-221.
[9] 李南,田慧敏,邓丹. 团队知识学习的网络建模及分析[J].中国机械工程,2006,17(22):2366-2369.
[10] 王寅,张英华,王饶,等.组织双元性创新模式演化路径研究-两种次优能力陷阱讨论[J].科技进步与对策,2016,33(8):93-10.
[11] 穆文奇,郝生跃,任旭,等.企业动态能力倒U型作用的实证研究[J].软科学,2016,30(12):89-94.
[12] 张志华,陈向东.企业学习方式、创新能力与创新绩效关系的实证研究[J].系统管理学报,2016,25(5):829-836.
[13] CANTNER U, MEDER A, TERWAL A L. Innovator networks and regional knowledge base[J]. Technovation, 2010, 30(9): 496-507.
[14] XIAO W, GAIMON C, CARRILLO J. Managing knowledge in a three-stage new product development project[C]. 2014 Proceedings of PICMET’14: Infrastructure and service integration: 1818-1826.
[15] LAURSEN K, SALTER A. Open for innovation: The role of openness in explaining innovation performance among UK manufacturing firms[J]. Strategic Management Journal, 2006, 27(2): 131-150.
[16] GIANLUCA C, ELISA OPERTI. Where do firms' recombinant capabilities come from? intraorganizational networks, knowledge, and firms' ability to innovate through technological recombination[J]. Strategic Management Journal, 2013, 34(13): 1591-1613.
[17] 张峥,高明明,陈清生.技术相似度对中国制造业并购创新绩效影响模拟[J].科技进步与对策,2016,33(19):69-75.
[18] CARRILLO J E, GAIMON C. Managing knowledge based resource capabilities under uncertainty[J]. Management Science, 2004, 50(11): 1504-1518.
[19] 薛捷,张振刚.技术及市场环境动荡中企业动态学习能力与创新绩效关系研究[J].科技进步与对策,2015,32(1):98-104.
(责任编辑:林思睿)
The Optimal Sequential Strategy of Learning Ambidexterity for High-tech Product R&D Project Based on the Knowledge Accumulation
Abstract:High-tech product is the integration of high-tech knowledge, and its R&D status has become one of the decisive factors in the growth of knowledge economy. Focused on the mechanism of organizational learning-knowledge stock-R&D performance, an optimal model of dynamic ambidexterity is introduced. After the model solving, results are obtained about the decision making of the optimal termination point, the optimal switching point, and the optimal input intensity of exploration and exploitation. Based on these results the optimal sequential ambidexterity strategy is given for the maximization of high-tech product's R&D performance. All of these conclusions can provide reference for the control of R&D rhythm, the formulation of learning strategy and the allocation of investment resources in the implementation of high-tech product development projects.
Key Words:R&D Project;Knowledge Stock;Organizational Learning;Optimal Control
收稿日期:2017-06-06
基金项目:国家社会科学基金项目(13CGL012)
DOI:10.6049/kjjbydc.2017030781
中图分类号:F406.3
文献标识码:A
文章编号:1001-7348(2017)16-0126-06